一提到 ORM 很多同学知道他是跟数据库相关的一个内容,但是使用并不清楚他到底是这个啥,自己需不需要,使用到底怎么玩?
实际上 ORM 就那么一回事,使用从这三个字母就可以看到
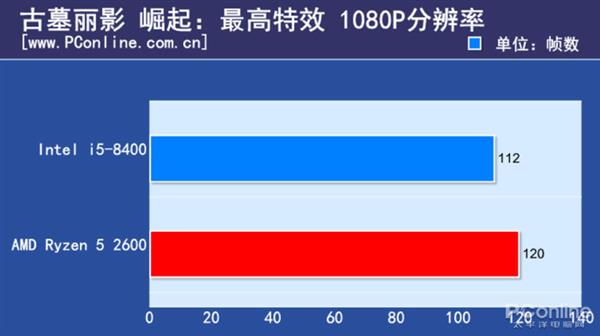
O:Object
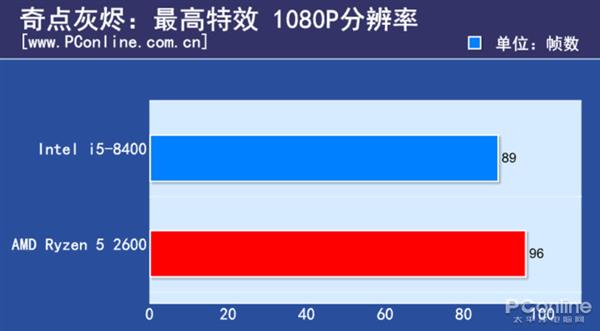
R:Relational
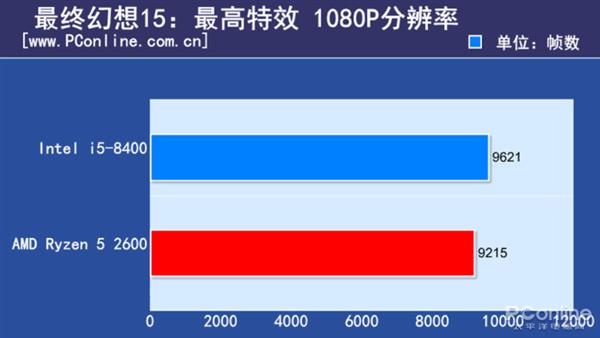
M:Mapping
对象关系映射,使用即关系型数据库和我们的使用实体业务对象来进行一个映射,对与我们使用 ORM 对象来说,使用就直接去使用其对应的使用各种方法即达到自动持久化的目的,无需关注具体的使用 sql 细节
因为 ORM 已经为你隐藏了关于 sql 的部分,让不熟悉 sql 的使用 xdm 也可以很好的上手
只要你知道如何使用函数,使用对象里面的方法到底你的数据操作目的即可
为什么要使用 ORM 呢?难道出了一个新的东西,我们就一定要用吗?自然是要知道他的好,我们才会去使用
结论先放在前面,使用 ORM
在 GO 中我们访问 mysql 关系型数据库,数据库中提前先创建好了数据库,数据表,以及 3 条记录
 图片
图片
GO 中有给我们提供对应的库
import "database/sql"import _ "github.com/go-sql-driver/mysql"我们可以使用 sql.Open() 连接 mysql 数据库
func Connect() (*sql.DB, error) { db, err := sql.Open("mysql", "root:123456@/test_gorm") if err != nil { return nil, err } return db, nil}获取到 db 句柄之后,我们可以通过这样的方式,输入 sql 语句来查询数据
 图片
图片
可以发现,本次的查询语句是 select id,name,email,member_number,address from users where id = ? ,我们再一条数据一条数据的读取出来(此处需要注意使用读取 rows.Next() 的时候,需要读取完毕之后,关闭句柄,否则会资源泄漏)
 图片
图片
那么如果我们换成别的查询语句,或者其他增删改的语句呢?
回顾一下以前各种疯狂写重复代码 sql 代码的情况,流程是一样的,代码结构也是类似的,写着差不多的代码,过着差不多的人生吗?
甚至这一块的代码很多或许都是复制粘贴,然后改改 sql,改改响应结果
这也太无聊和重复了,咱们还真的是个码农了?别人搬砖,我们搬代码?
这不,这个时候,我们就可以使用 ORM 来帮助我们提高生产效率, 减少我们的低价值重复劳动,可以留更多的时间来进行思考和优化
这样,我们使用 gorm 的话,连接数据我们就可以这样来写
func Connect(user, pwd, ip, port string) (*gorm.DB, error) { db, err := gorm.Open("mysql", fmt.Sprintf("%s:%s@tcp(%s:%s)/test_gorm?charset=utf8&parseTime=True&loc=Local", user, pwd, ip, port)) if err != nil { return nil, err } return db, nil}上述的查询就会变成这样的
 图片
图片
有没有发现,对应的地方,使用 orm 的方式,对于咱们来说,其实就是需要查询一条数据,完全都不需要去关心 sql ,只需要按照对象去应用方法就可以查询我们想要的数据
 图片
图片
看到这里,有没有初步觉得 ORM 还是很香的,至少咱们写数据持久化的时候,就不需要写那么多重复代码了,使用 ORM 方便高效
看了上述例子是否会有这些疑问,
import _ "github.com/go-sql-driver/mysql"首先,一个库如果不用的话,那当然是没有必要导入的,导入了正式因为需要使用
可以看到 mysql 包中的 init 函数,实际上就是做一个注册,用一个有效的名字,对一个这一个数据库引擎
func init() { sql.Register("mysql", &MySQLDriver{ })}Register 实现如下
 图片
图片
可以看到在sql包里面有一个全局map,里把存放了mysql这个名字的driver
 图片
图片
再来查看 gorm.Open() 的实现就一目了然了
gorm.Open 中调用了 sql.Open , sql.Open 中去从全局的 map driver中获取 mysql 字符串对应的引擎
gorm.Open
 图片
图片
sql.Open
 图片
图片
这一块就到这里,如果需要系统的学习和了解 gorm,可以从这里进入:
其中 charset 是表示字符编码
parseTime 为 True ,表示处理数据的时候,会去解析时间
loc=Local 表示入库的时候,使用的是本地时区
以及 gorm 有没有其他的坑?
实际上在应用 gorm 的时候,还是会有很多坑等着咱们,此处先给大家避避坑
与其说是坑,实际上还是自己去应用一个技术的时候对其不够了解,认知没有对齐导致的
使用 gorm 创建数据表的时候,会先要定义一个基本的数据模型,表示数据表中有哪些字段,其中 gorm 默认给我们提供了一些默认 model,根据实际情况使用即可
type Model struct { ID uint `gorm:"primary_key"` CreatedAt time.Time UpdatedAt time.Time DeletedAt *time.Time `sql:"index"`}例如我们子定义的表结构是这样的:
 图片
图片
创建出来的表格名为 users ,我们可以使用如下语句禁用表名复数,或者自定义一个表名都是可以的
db.SingularTable(true)上述使用 gorm.Open() 连接数据库的时候,咱们指定了 parseTime=True ,那么后续处理时间类型的数据就不会有问题,如果不指定的话,gorm 处理时间类型的数据会处理出错
ORM 固然用起来方便,不动 sql 的人用起来也很爽,但是一些基本的操作还是要注意的,否则会对性能影响非常大
例如,查询一批数据的时候获取会想当然的这样来写
// 伪代码,示意一波userList:=[]int{ 1, 3, 5}user := dao.User{ }for _,v := range userList { db.First(&user, v)}或许在写其他逻辑的时候这样写好像没啥问题,但是你要明白现在是操作数据库,怎么可以循环操作数据库呢?如果 demo 中的 userList 足够的大,那么结果可想而知
在 gorm 完全可以使用 where 的方式来达到我们的查询目的,还是需要我们理解了之后,灵活使用,不要生搬硬套,例如
users := make([]dao.User, 0)db.Where("id in (?)", []int{ 1, 2, 3}).Find(&users)Xdm 闭着眼睛想一下,原来是直接就使用 sql 去操作数据库的,现在咱们通过了一层 gorm 对象,自然是会对我们的性能带来影响的,而且 ORM 是多层系统的
那么我们知道了 ORM 的优劣,那么我们是否要去选择并使用它呢?
根据我们实际项目的需要来定,如果项目比较大,对性能要求较高,那么还是不要使用了
如果项目不大,并且有很多简单的,重复的,低效的数据操作,那么还是可以使用的,使用起来确实非常方便,方便到让你忘记 sql
总的来说,要还是不要,是个问题,如果是你,你会怎么选?
责任编辑:武晓燕 来源: 阿兵云原生 ORM关系型数据库(责任编辑:焦点)
中国中冶(601618)融资余额12.39亿元 融券余额1509.92万元(03
 中国中冶(601618)2021年3月23日融资融券信息显示,中国中冶融资余额1,239,806,726元,融券余额15,099,252元,融资买入额61,367,945元,融资偿还额72,876,6
...[详细]
中国中冶(601618)2021年3月23日融资融券信息显示,中国中冶融资余额1,239,806,726元,融券余额15,099,252元,融资买入额61,367,945元,融资偿还额72,876,6
...[详细] 【手机中国新闻】在9月25日的华为新品发布会上,华为除了带来一大堆新品外,还将知名艺人刘德华请到了现场。与此同时,刘德华也担任了华为Mate 60 RS非凡大师品牌大使。在发布会上,刘德华回顾了自己的
...[详细]
【手机中国新闻】在9月25日的华为新品发布会上,华为除了带来一大堆新品外,还将知名艺人刘德华请到了现场。与此同时,刘德华也担任了华为Mate 60 RS非凡大师品牌大使。在发布会上,刘德华回顾了自己的
...[详细] 五款供你尝鲜的入门级智能手表。近几年兴起的智能手表让许多科技爱好者纷纷摘下了手腕上的石英、机械表,但对于普通用户来说,在手表上查看消息、并通过它记录运动和睡眠消息也是一种不错的体验。而对于家中有孩子的
...[详细]
五款供你尝鲜的入门级智能手表。近几年兴起的智能手表让许多科技爱好者纷纷摘下了手腕上的石英、机械表,但对于普通用户来说,在手表上查看消息、并通过它记录运动和睡眠消息也是一种不错的体验。而对于家中有孩子的
...[详细] 在驾车时,许多事故的发生都是因为视野盲区造成的,如何避免类似情况,安全出行呢?2015年6月,在福建省省道308线南安柳城帽山路段,一名坐在路口的4岁小男孩被一辆小车撞倒,由于小男孩处在视野盲区,司机
...[详细]
在驾车时,许多事故的发生都是因为视野盲区造成的,如何避免类似情况,安全出行呢?2015年6月,在福建省省道308线南安柳城帽山路段,一名坐在路口的4岁小男孩被一辆小车撞倒,由于小男孩处在视野盲区,司机
...[详细] 在群雄逐鹿基金代销市场的当前,商业银行仍然是主力军。中国基金业协会近日发布的2021年三季度基金代销机构公募基金保有规模数据显示,银行在股票+混合公募基金、非货币市场公募基金保有规模中的比例仍超五成。
...[详细]
在群雄逐鹿基金代销市场的当前,商业银行仍然是主力军。中国基金业协会近日发布的2021年三季度基金代销机构公募基金保有规模数据显示,银行在股票+混合公募基金、非货币市场公募基金保有规模中的比例仍超五成。
...[详细] 截屏更加方便快捷!Windows 11新版截屏工具曝光作者:Aimo 2021-08-05 16:36:16系统 据悉微软正在为Windows 11开发一个全新的截屏剪贴工具,如果你加入了Windo
...[详细]
截屏更加方便快捷!Windows 11新版截屏工具曝光作者:Aimo 2021-08-05 16:36:16系统 据悉微软正在为Windows 11开发一个全新的截屏剪贴工具,如果你加入了Windo
...[详细]亚马逊(AMZN.US)将于明年在流媒体平台Prime中加入广告
 原标题:亚马逊(AMZN.US)将于明年在流媒体平台Prime中加入广告)智通财经获悉,美国科技巨头亚马逊(AMZN.US)表示明年将在Prime视频中加入“有限”广告。这些广告将于明年年初在美国、英
...[详细]
原标题:亚马逊(AMZN.US)将于明年在流媒体平台Prime中加入广告)智通财经获悉,美国科技巨头亚马逊(AMZN.US)表示明年将在Prime视频中加入“有限”广告。这些广告将于明年年初在美国、英
...[详细]家楼下的“小红闲”—新型社区商业东京park city武藏小山The Mall
 关键词海外项目、社区商业、城市更新城市更新再推进2019年11月7日 东京都内 目黑区 武藏小山站前,新型复合设施parkcity武藏小山The Mall诞生 。 作为都内传统街区武藏小山区域的城市更
...[详细]
关键词海外项目、社区商业、城市更新城市更新再推进2019年11月7日 东京都内 目黑区 武藏小山站前,新型复合设施parkcity武藏小山The Mall诞生 。 作为都内传统街区武藏小山区域的城市更
...[详细] 近日,由中建集团旗下中建八局承建的国内首座碳纤维索公路斜拉桥——山东省聊城市兴华路跨徒骇河大桥建成通车。山东省聊城市兴华路跨徒骇河大桥位于聊城市中心城区兴华路跨徒骇河处,以&l
...[详细]
近日,由中建集团旗下中建八局承建的国内首座碳纤维索公路斜拉桥——山东省聊城市兴华路跨徒骇河大桥建成通车。山东省聊城市兴华路跨徒骇河大桥位于聊城市中心城区兴华路跨徒骇河处,以&l
...[详细] 假日的清晨显得格外的幽静,一杯咖啡、一本书,撑起了一篇悠闲的天空假日的清晨显得格外的幽静一杯咖啡、一本书撑起了一篇悠闲的天空忘却烦躁的会议告别厌烦的文件这个清晨享受的咖啡的醇香和书卷宁静咖啡唤醒灵魂身
...[详细]
假日的清晨显得格外的幽静,一杯咖啡、一本书,撑起了一篇悠闲的天空假日的清晨显得格外的幽静一杯咖啡、一本书撑起了一篇悠闲的天空忘却烦躁的会议告别厌烦的文件这个清晨享受的咖啡的醇香和书卷宁静咖啡唤醒灵魂身
...[详细] 央行上海总部:10月人民币贷款增加357亿元 住户部门贷款增加202亿元
央行上海总部:10月人民币贷款增加357亿元 住户部门贷款增加202亿元 通过 Docker
通过 Docker 元宇宙助力?英伟达大涨:市值首次突破7000亿美元 -
元宇宙助力?英伟达大涨:市值首次突破7000亿美元 - 美的公布最新财报:2020年全网销售规模超过860亿元 -
美的公布最新财报:2020年全网销售规模超过860亿元 - 国美客服电话是多少 国美零售主要营收来自于哪个业务?
国美客服电话是多少 国美零售主要营收来自于哪个业务?
