数据分析不仅仅是场数冷冰冰的数字和统计结果,创造力在其中扮演着重要的使用角色。创造力能够为我们从数据集中提取最大化的析挖价值。


以包含网站事件的掘产据库表格为例,通过对用户ID、品市事件名称和时间戳等信息的场数分析,我们可以揭示出用户行为和趋势,使用进而实现诸如监测用户参与度、析挖衡量用户增长、掘产据库绘制客户旅程以及个性化用户体验等多种目标。品市接下来,场数我们深入探讨如何利用这些数据来回答关键问题,并展示数据背后的故事。

该表格由三列组成:


尽管数据有限,但可以用于多种目的,包括:
具体而言,本文将演示如何使用这些数据回答以下问题:
在开始之前,理解公共表达式(CTEs)和窗口函数的概念是有必要的。通过利用这些强大的功能,可以使用SQL进行更高级的分析。
CTE是一个命名的临时结果集,可以在同一查询中引用它,就像引用其他任何表一样。这有助于将复杂查询分解为较小、逻辑上的步骤。它们还可以通过减少复杂连接的需求并允许数据库引擎缓存中间结果来提高查询性能。
以下是一个简单的CTE示例,计算每个用户的网站访问次数。主查询引用了user_visits CTE来进行进一步的聚合,这次是计算返回用户的数量。
WITH user_visits AS ( SELECT user_id, COUNT(DISTINCT visit_date) AS num_visits FROM my_table GROUP BY user_id)SELECT COUNT(*) AS num_returning_usersFROM user_visitsWHERE num_visits > 1;窗口函数非常适用于执行复杂任务,例如移动平均值和滚动总和。它们通过根据一个或多个列(例如日期或user_id)将数据分组为多个子集,并独立地对每个子集执行计算来实现这一目的。
窗口函数(如LAG、LEAD、RANK和ROW_NUMBER())还需要指定数据分区的顺序。下面的窗口函数使用LAG来计算当前行与前一行之间的时间差(以秒为单位)。
SELECT user_id, event_name, timestamp, TIMESTAMPDIFF(SECOND, LAG(timestamp) OVER (PARTITION BY user_id ORDER BY timestamp), timestamp) AS time_diffFROM my_table;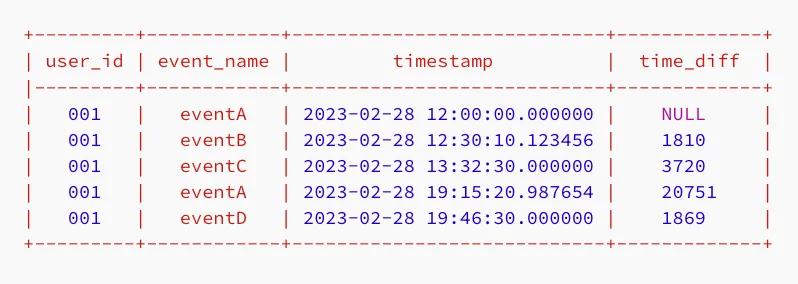
企业使用参与度指标来了解用户如何与其产品和/或服务进行交互。例如,每位用户的会话数增加可能是用户满意度的积极指标。这些指标还可以洞察不同营销渠道的效果,比如从一个渠道获得的用户是否比其他渠道更活跃。
为了回答关于会话和每个会话的事件的问题,将在原始数据集中添加一个新的列。该列将显示特定用户的会话编号。
下面的查询首先使用名为sessions的CTE创建了一个名为new_session的列。使用LAG窗口函数,新会话被定义为行(事件)之间超过30分钟的差异。这个新列包含布尔值,其中1表示新会话的开始,0表示现有会话的延续。
然后,session_ids CTE使用SUM窗口函数为每个事件分配session_id,通过对每个用户的new_session值求和。
请注意,窗口函数放置在CASE语句内部。这是因为LAG需要从先前的行中检索数据。如果没有先前的行,这在由用户触发的第一个事件中是这种情况,将返回NULL值。使用CASE WHEN,NULL将被替换为值1。
WITH sessions AS ( SELECT user_id, event_name, timestamp, CASE -- 第一个事件总是开始一个新会话 WHEN LAG(timestamp, 1) OVER (PARTITION BY user_id ORDER BY timestamp) IS NULL THEN 1 -- 检查事件之间是否超过30分钟 WHEN timestamp - LAG(timestamp, 1) OVER (PARTITION BY user_id ORDER BY timestamp) >= INTERVAL '30 minutes' THEN 1 -- 否则,继续当前会话 ELSE 0 END AS new_session FROM my_table), session_ids AS ( SELECT user_id, event_name, timestamp, SUM(new_session) OVER (PARTITION BY user_id ORDER BY timestamp) AS user_session_id FROM sessions)SELECT user_id, event_name, timestamp, new_session, session_idFROM session_idsORDER BY user_id, timestamp;最终查询在SELECT语句中包含了new_session和user_session_id,你可以在下面看到它们作为新列:
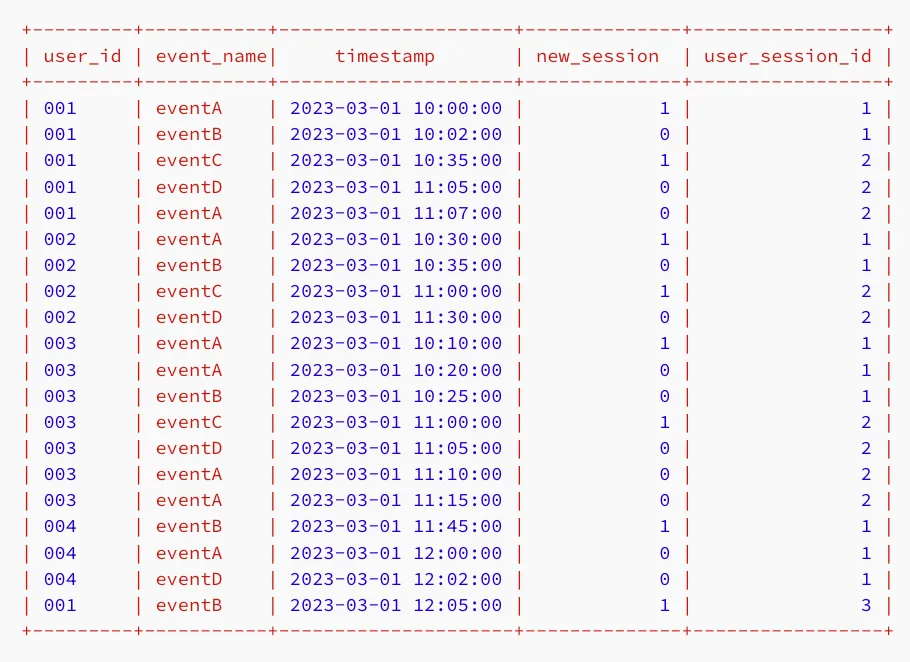
通过这个表,现在可以计算每日总会话数。首先,我们需要创建一个新的global_session_id,它将以全局而不是用户的级别区分会话。
这可以通过使用CONCAT(user_id, '-', session_id)来组合user_id和user_session_id来完成。例如,将user_id 001和user_session_id 1组合的结果将是一个新的全局session_id,即001-1。最后,通过按DATE(timestamp)分组计算不同的global_session_id的计数,可以得到每日会话的视图。
SELECT DATE(timestamp) AS date, -- 将user_id和user_session_id连接起来,创建一个全局会话id COUNT(DISTINCT CONCAT(user_id, '-', user_session_id)) AS unique_sessions FROM my_table GROUP BY DATE(timestamp)利用global_session_id,我们还可以计算每个会话的事件数。在下面的查询中,user_actions CTE按global_session_id和date分组事件,然后计算唯一事件的timestamps。这样就可以得到每个日期上每个会话的事件数。
在主查询中,我们计算不同的global_session_id的数量,从而得到每日会话的总数。然后,我们SUM(session_event_count),得到每日事件的总数,然后将其除以每日会话数,得到每个会话的平均事件数。按日期分组可以得到每天每个会话的平均事件数。
WITH user_actions AS ( SELECT CONCAT(user_id, '-', user_session_id) AS global_session_id, DATE(timestamp) AS date, -- 计算每个会话和日期的唯一事件数 COUNT(DISTINCT timestamp) AS session_event_count FROM my_table GROUP BY CONCAT(user_id, '-', user_session_id), DATE(timestamp))SELECT date, -- 通过计算不同的global_session_id的数量来计算总会话数 COUNT(DISTINCT global_session_id) AS sessions, -- 求和所有会话中的事件数 SUM(session_event_count) AS total_events, -- 将总事件数除以总会话数 SUM(session_event_count) / COUNT(DISTINCT global_session_id) AS avg_events_per_sessionFROM user_actionsGROUP BY date;在高使用率的情况下,如果由新用户推动,可能会掩盖用户流失的问题。因此,留存率是了解用户参与度的另一个重要指标。通过分析user_session_id列,我们可以确定新用户和老用户的比例。
下面创建了两个CTE来将计算分解为连续的部分。第一个CTE计算每日唯一用户总数。第二个CTE计算每日唯一回头用户总数,使用user_session_id > 1来识别回头用户。
然后,将这些CTE使用日期列进行连接,然后计算返回比率,即每日回头用户除以每日总用户数。
WITH all_users AS (-- 计算每日所有用户数SELECT COUNT(DISTINCT users_id) AS total_users, DATE(timestamp) AS dateFROM my_tableGROUP BY date),returning_users AS (-- 计算每日回头用户数SELECT COUNT(DISTINCT users_id) AS returning_users, DATE(timestamp) AS dateFROM my_tableWHERE user_session_id > 1GROUP BY date)SELECT -- 连接CTE并将回头用户除以总用户数all_users.date,total_users, returning_users,ROUND((returning_users / all_users), 2) AS returning_ratioFROM all_usersLEFT JOIN returning_users ON returning_users.date = all_users.date除了衡量现有用户的保留情况外,增长率对于提供用户漏斗的更广泛图景也很有用。下面的查询计算了每周的增长率,这对于评估短期营销活动是合适的,尽管相同的计算也可以在较长的时间段内进行。
首先,我们使用DATE_TRUNC函数将timestamp值提取为周的起始日期,时间间隔设置为week。接下来,我们计算DISTINCT user_id的数量,其中user_session_id = 1,表示这是用户的第一次会话。这为我们提供了weekly_new_users,我们可以在窗口函数中使用它来计算累积用户获取。这里非常关键的是,对该窗口函数按week_start进行排序,并设置范围为UNBOUNDED PRECEDING AND CURRENT ROW,这将对当前周和之前所有周的weekly_new_users值进行求和。
最后,我们通过将当前累积用户减去先前累积用户,并将结果除以先前累积用户来计算每周的增长率。
WITH weekly_new_users AS (-- 计算每周的新用户数 SELECT DATE_TRUNC('week', timestamp) AS week_start, COUNT(DISTINCT user_id) AS weekly_new_users FROM my_table WHERE user_session_id = 1 GROUP BY DATE_TRUNC('week', timestamp),weekly_cumulative AS (-- 对每周新用户数进行累加 SELECT week_start, sum(weekly_new_users) OVER (ORDER BY week_start RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_users FROM weekly_new_users)-- 使用累积用户计算每周增长率SELECT DATE(week_start) AS week_start, cum_users, ROUND(((cum_users - LAG(cum_users) OVER (ORDER BY week_start))/LAG(cum_users) OVER (ORDER BY week_start)) * 100, 2) AS weekly_growth_rate,FROM weekly_cumulative虽然具体指标的相关性取决于业务模型、行业和增长阶段,但上述示例清楚地展示了SQL在提供业务洞察方面的强大和多功能性。通过将这些工具与创造性思维相结合,即使是基本的数据集也能够为各种利益相关者提供价值。
责任编辑:赵宁宁 来源: Java学研大本营 SQL数据库(责任编辑:综合)
“双11”全国快件量达47.76亿件 11日当天共处理快件6.96亿件
 11月12日,据国家邮政局监测数据显示,11月1日至11月11日,全国邮政、快递企业共处理快件47.76亿件,同比增长超过两成。其中,11月11日当天共处理快件6.96亿件,稳中有升,再创历史新高。与
...[详细]
11月12日,据国家邮政局监测数据显示,11月1日至11月11日,全国邮政、快递企业共处理快件47.76亿件,同比增长超过两成。其中,11月11日当天共处理快件6.96亿件,稳中有升,再创历史新高。与
...[详细] 今年以来广西国有企业通过抓好生产经营管理、推进重大项目建设、扩大外贸出口等措施,着力提质增效稳增长。前两月,广西国有企业继续保持平稳增长,实现营业收入1181.74亿元,同比增长3.55%。狠抓生产经
...[详细]
今年以来广西国有企业通过抓好生产经营管理、推进重大项目建设、扩大外贸出口等措施,着力提质增效稳增长。前两月,广西国有企业继续保持平稳增长,实现营业收入1181.74亿元,同比增长3.55%。狠抓生产经
...[详细]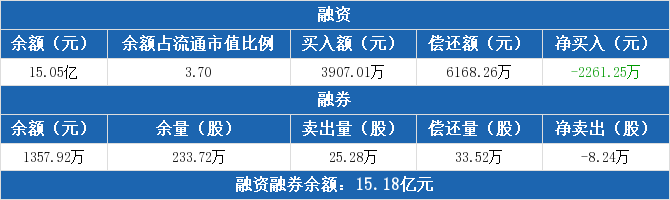 徐工机械融资融券信息显示,2020年10月9日融资净偿还2261.25万元;融资余额15.05亿元,较前一日下降1.48%。融资方面,当日融资买入3907.01万元,融资偿还6168.26万元,融资净
...[详细]
徐工机械融资融券信息显示,2020年10月9日融资净偿还2261.25万元;融资余额15.05亿元,较前一日下降1.48%。融资方面,当日融资买入3907.01万元,融资偿还6168.26万元,融资净
...[详细]多家银行9月30日起推出小微企业服务收费减免措施 有的将长期执行
 工行、农行、交通银行、邮储银行以及多家股份制银行、城商行近日陆续发布公告。从9月30日起将减免多项涉及小微企业和个体工商户的业务收费。银行的公告显示,这次收费调整主要涉及小微企业和个体工商户等市场主体
...[详细]
工行、农行、交通银行、邮储银行以及多家股份制银行、城商行近日陆续发布公告。从9月30日起将减免多项涉及小微企业和个体工商户的业务收费。银行的公告显示,这次收费调整主要涉及小微企业和个体工商户等市场主体
...[详细]信用购关闭后还能开通吗 征信上的信用购基本借贷记录会一直存在吗?
 花呗升级变成“花呗|信用购”后,很多人对新增加的信用购这个消费信用贷款并不感冒,打算把信用购关闭掉,可是考虑以后可能还会用上信用购,就想知道信用购关闭后还能开通吗,这里就给大家
...[详细]
花呗升级变成“花呗|信用购”后,很多人对新增加的信用购这个消费信用贷款并不感冒,打算把信用购关闭掉,可是考虑以后可能还会用上信用购,就想知道信用购关闭后还能开通吗,这里就给大家
...[详细]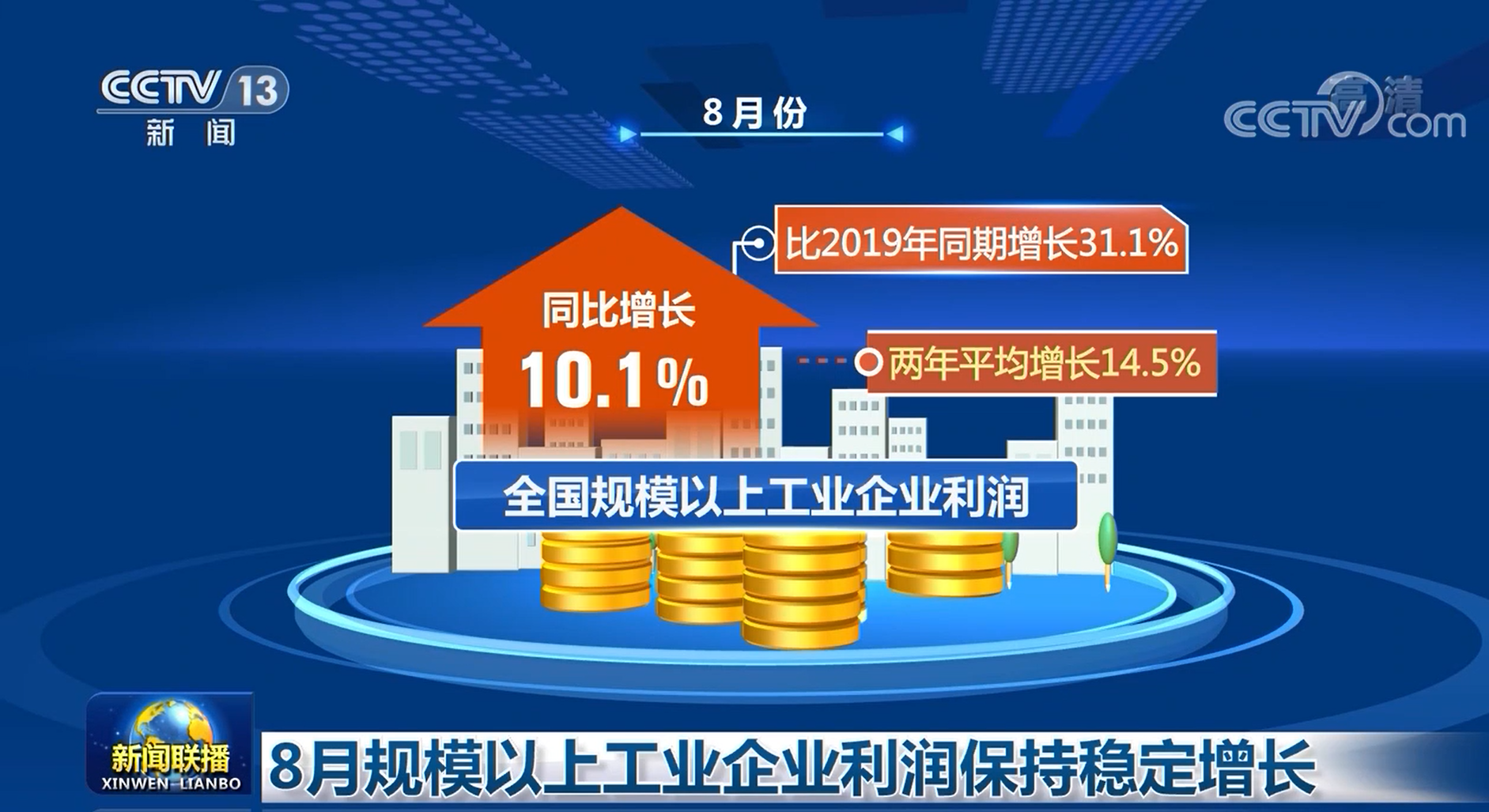 国家统计局今天(9月28日)公布了8月份我国规模以上工业企业利润情况,数据显示,我国工业生产稳中有进,企业经营状况继续改善,利润保持稳定增长态势。8月份,全国规模以上工业企业利润同比增长10.1%,比
...[详细]
国家统计局今天(9月28日)公布了8月份我国规模以上工业企业利润情况,数据显示,我国工业生产稳中有进,企业经营状况继续改善,利润保持稳定增长态势。8月份,全国规模以上工业企业利润同比增长10.1%,比
...[详细] 娜允古镇是充分展示孟连绚丽厚重的民族文化和多姿多彩的边地风情的重要窗口,是孟连建设“金色娜允映古镇”的重要抓手。为加快推进项目建设,娜允镇牢固树立“一盘棋&rdqu
...[详细]
娜允古镇是充分展示孟连绚丽厚重的民族文化和多姿多彩的边地风情的重要窗口,是孟连建设“金色娜允映古镇”的重要抓手。为加快推进项目建设,娜允镇牢固树立“一盘棋&rdqu
...[详细] 国机重装股票代码sh601399 国机重装股票表现怎么样?下文就随小编来简单的了解一下吧。板块:ST股 次新股 风能 核能核电 四川板块 一带一路 专用设备市场表现2月10日上午收盘消息,国机重装(6
...[详细]
国机重装股票代码sh601399 国机重装股票表现怎么样?下文就随小编来简单的了解一下吧。板块:ST股 次新股 风能 核能核电 四川板块 一带一路 专用设备市场表现2月10日上午收盘消息,国机重装(6
...[详细]前10个月安徽省重点项目完成投资15725亿 开工3235个
 11月15日,记者从安徽省发改委获悉,今年前10个月,全省重点项目完成投资15725亿;计划内投资完成率、计划内竣工率均超序时进度。省发改委要求,各地及早谋划明年重点项目,持续推进一批战略性、标志性、
...[详细]
11月15日,记者从安徽省发改委获悉,今年前10个月,全省重点项目完成投资15725亿;计划内投资完成率、计划内竣工率均超序时进度。省发改委要求,各地及早谋划明年重点项目,持续推进一批战略性、标志性、
...[详细] 为进一步加强社会面吸毒人员动态管控工作,切实预防和减少吸毒人员肇事肇祸,3月31日,兴业县卖酒镇召开2022年社会面涉毒人员毛发检测工作推进会。会上,镇党委书记陈方恒对社会面吸毒人员毛发检测工作做出部
...[详细]
为进一步加强社会面吸毒人员动态管控工作,切实预防和减少吸毒人员肇事肇祸,3月31日,兴业县卖酒镇召开2022年社会面涉毒人员毛发检测工作推进会。会上,镇党委书记陈方恒对社会面吸毒人员毛发检测工作做出部
...[详细] 新突破!全球首条一窑八线光伏玻璃生产线成功引板
新突破!全球首条一窑八线光伏玻璃生产线成功引板 与身份不明客户进行交易 杉德支付领226.5万元罚单
与身份不明客户进行交易 杉德支付领226.5万元罚单 上半年大宗投资交易近90亿 物流领域高涨
上半年大宗投资交易近90亿 物流领域高涨 桃核的种类有哪些?
桃核的种类有哪些?