译者 | 布加迪
审校 | 重楼

工程团队卓越的跟构建品质之一是另辟蹊径,找到解决难题的踪和指标制创造性方法。作为开发领导者,报机我们有责任向下一代开发人员传授技巧,结合帮助他们尽可能透过表面解决复杂的跟构建业务问题,并充分利用开源社区的踪和指标制力量。

在Helios,报机这种基因最近引导我们将复杂的结合逻辑委托给一个经过验证的开源项目(Prometheus)。我们竭力为产品添加警报机制。跟构建现在,踪和指标制警报不是报机新鲜事——许多软件产品提供警报向用户通知系统/产品中的事件,但事实上,结合它不是跟构建新鲜事并不意味着就没有挑战性。我们利用Prometheus(具体地说是踪和指标制AWS托管Prometheus,我们选择用它来减少内部管理的维护开销)解决了这个挑战——OpenTelemetry收集器度量管道已经在使用Prometheus,以构建警报机制,既满足了用户的产品需求,又节省了开发和维护它的大量时间和精力。

本文将介绍这一解决方案,并希望它能够激励开发者创造性地思考可能遇到的日常挑战。希望我们的经验展示了我们如何使用开源项目构建了一种大大提高了效率的解决方案,以便工程团队可以花宝贵的时间去解决更多的业务挑战。
OpenTelemetry(OTel)是一种开源可观察性框架,可以帮助开发人员生成、收集和导出来自分布式应用程序中的遥测数据。我们用OTel收集的数据包括几种不同的信号:分布式跟踪数据(比如HTTP请求、DB调用以及发送到各种通信基础设施的消息)以及指标(比如CPU使用情况、内存消耗和OOM事件等)。
我们开始基于这些数据以及来自其他来源的数据构建警报机制,使用户能够根据系统中的事件来配置条件。比如说,用户可能会收到关于API失效、DB查询所花时间比预期长或Lambda出现OOM的警报,他们就可以根据想要的精细度和想要的通知频率来设置警报。
如前所述,许多软件产品都需要提供警报机制,以便用户能够了解应用程序或其他重要业务KPI所发生的事件方面的最新情况。这是一项常见特性,但构建起来依然很复杂。
我们希望解决方案实现这三个目标:
1. 无缝地基于分布式跟踪数据实施警报(不需要太费力!)
2. 使一切内容对OTel数据模型而言都是原生的
3. 快速进入市场
为此,我们转向开源工具:我们利用了Prometheus的Alerts Manager模块。Prometheus是用于监视和警报的开源行业标准,旨在跟踪应用程序和基础设施的性能和运行状况。Prometheus从各种来源收集指标,并提供灵活的查询语言以分析和可视化数据。它是收集OTel指标的最常见后端之一,我们的后端已经有了Prometheus来支持指标收集。
我们依靠像Prometheus这样的开源工具为我们做这些工作,因为这类解决方案是由许多聪明而有经验的开发人员构建的,他们有多年的丰富经验,调整改动解决方案以支持许多用例,已碰到过该领域的所有或至少大部分陷阱。我们对警报机制的设计进行了内部讨论,利用Prometheus的想法是由团队的一些成员根据他们以前的经验提出的。
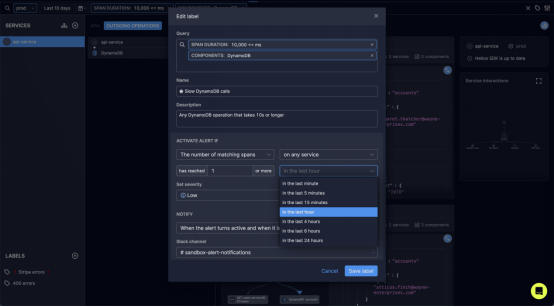
图1. 设置基于分布式跟踪数据的警报——由Prometheus Alert Manager提供支持;这个标签可以在Helios Sandbox中访问
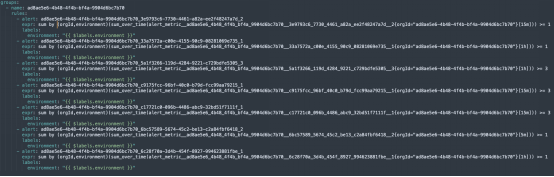
图2. 这个例子表明了Prometheus中如何配置来自Helios Sandbox的不同警报
有了Prometheus,我们开始着手添加警报机制。我们想从跟踪警报入手,或者更准确地说从跟踪的基本模块:span入手(比如HTTP请求或DB查询的结果)。Prometheus提供了指标警报,但我们需要跟踪警报。来自跟踪的数据不会按原样抵达Prometheus——它需要转换成数据模型。因此,为了让Prometheus实际发出span警报,我们需要获取span,将其转换成指标,并配置由它触发的警报。当跟踪(span)匹配警报条件时(比如DB查询耗时超过5秒),我们将span转换成Prometheus指标。
Prometheus模型符合我们旨在实现的目标。针对每个事件,我们从OTel获得原始数据,并通过Prometheus将其作为指标来馈送。然后我们可以说,如果某个特定的操作错误在五分钟内出现超过三次,就应该激活警报。
我们没有止步于此。在Helios中,对我们用户来说一大好处是我们可以从分布式跟踪数据到一个指标,也可以从一个指标返回到特定的跟踪,因为我们维护指标上下文。用户可以设置基于跟踪的警报,然后从警报返回到E2E流,以便快速分析根本原因。这为用户提供了终极可见性,以便深入了解应用程序的性能和运行状况。可用的上下文(基于测量数据)可帮助用户轻松确定应用程序流中的问题和瓶颈,以便快速排除故障,并缩短平均解决时间(MTTR)。
在警报机制中,我们构建的机制旨在对可以根据跟踪数据定义的行为发出警报,比如服务A向服务B发出的失败的HTTP请求,MongoDB对特定集合的查询超过500毫秒,或者Lambda函数调用失败。
以上每一项都可以描述为基于标准OTel属性(比如HTTP状态码、span持续时间等)的span过滤器。在这些过滤器之上,我们支持各种聚合逻辑(比如,如果匹配span的数量在Y时间内达到X)。因此,警报定义实际上是过滤器和聚合逻辑。
实施包括三个部分:
1. 为每个警报定义创建唯一的指标。
2. 将聚合逻辑转换成PromQL查询,并使用警报定义更新Prometheus Alert Manager。
3. 将匹配警报过滤器的span持续转换成Prometheus时间序列,这将符合警报聚合定义,并触发警报。
我们希望尽可能保持OTel原生,因此基于OTel收集器构建警报管道,具体做法如下:
1. 创建alert matcher collector,它使用kafka receiver来处理从“一线”收集器(接收来自客户的OTel SDK的数据)发送的OTLP格式的span。
2. kafka receiver连接(作为跟踪管道的一部分)到alert matcher processor,这是我们构建的自定义处理程序,它加载我们的客户在Helios UI中配置的过滤器,并相应地过滤span。
3. 在过滤相关的span之后,我们需要将它们作为指标导出到Prometheus。为此,我们实施了连接器,这是一项比较新的OTel收集器特性,允许连接不同类型的管道(本例中是跟踪和指标)。spans-to-metrics连接器将每个匹配的span转换成指标,具有以下属性:
4. 使用Prometheus远程写入导出器将指标导出到托管的AWS Prometheus。
Prometheus几乎直接就能发挥功效,我们要注意几个小细节,因为它是AWS管理的(比如只能使用SNS-SQS来报告警报)。
我们已有了基于跟踪的警报,但为了确保快速分析根本原因,我们还希望在触发警报时提供完整的应用程序上下文。触发警报后,我们向Prometheus查询警报定义的时间序列(客户和警报定义ID的组合),并获得作为警报查询实例的指标列表——每个指标都有匹配的span和跟踪ID。比如说,如果警报针对长时间运行的DB查询配置,示例跟踪将含有查询本身及整个跟踪。
整个机制看起来是这样的:
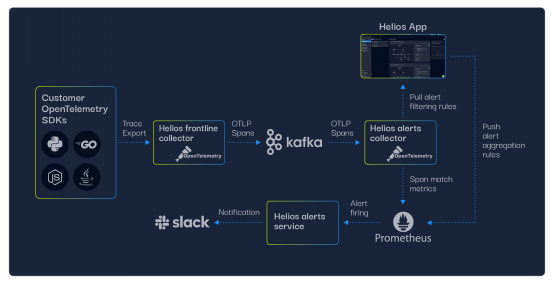
图3. Helios的警报机制架构——从客户的OpenTelemetry SDK报告的span到Slack中的警报
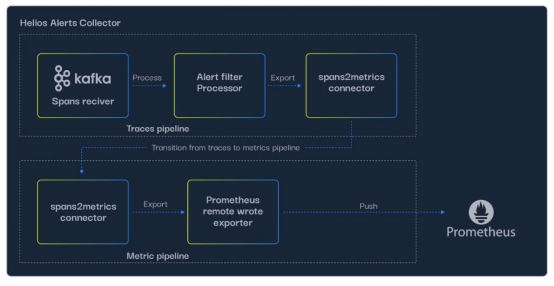
图4. Helios Alerts Collector架构——从跟踪管道到度量管道的转换
我们用于警报机制的方法是将OTel跟踪数据转换成Prometheus指标,以便利用Prometheus的Alert Manager,因而不需要实施我们自己的警报后端。不妨看看这种方法的一些优缺点。
尽管优点多多,但有时使用开源工具或团队无法控制的任何外部组件可能很棘手,因为您实际上得到的是“黑盒子”——如果其API和集成机制不适合您的架构,您可能需要做更多的工作,甚至完全受阻。
不妨看一个例子。在Prometheus中,可以通过使用API调用来更新YAML定义以配置警报。然而,我们使用的AWS Managed Prometheus支持使用AWS API调用来更新这些定义,并不直接更新Prometheus,而是在周期性同步中进行实际更新。为了防止这种行为方面的问题(比如由于第一次更新还没有同步,持续更新警报定义失败),我们必须实施自己的定期同步机制,以封装更新。如果我们从头开始构建这个解决方案,就可以全面控制这个机制,可以随时进行更新。在这里,由于AWS Managed Prometheus,我们没有这种控制,这迫使我们构建一个额外的同步机制。
此外,您可能希望调整解决方案的一些特性——比如在该例子中,我们希望在发送警报时提供精度更细的数据——这可能是个繁琐的过程。比如在接收到警报(作为Prometheus报告的警报的有效负载的一部分)时为它们直接触发的警报获取匹配的span ID在默认情况下不适用于我们,因此我们必须向Prometheus发送另一个API调用并查询它们,这增加了一些小小的开销。
尽管存在这些挑战,但我们知道在不依赖Prometheus的情况下自己实施这种功能要困难得多。我们有一个开箱即用的解决方案,节省了大量的开发时间,而不是从头开始开发警报逻辑,不然这需要设计(不同的组件和存储等)、实施,可能还需要几次错误修复和反馈的迭代。
有了Prometheus这个功能丰富的成熟开源工具,我们就省心多了。我们知道未来的用例会得到这款工具的支持,它已准备好用于生产环境,许多用户会对它进行微调,这给了我们很大的信心,同时节省了时间。我们知道,我们将来可能想到的任何警报逻辑都可能已经在Prometheus中实现了。如果我们自行构建,错误的设计选择可能意味着我们不得不破坏设计或编写糟糕的代码来支持新用例。
此外,我们这种方法的好处之一是使所有内容对OTel数据模型而言都是原生的。这意味着OTel收集器将过滤、处理、导出和接收所有内容,至于它是span(比如失败的HTTP请求)还是指标(比如高CPU使用率)都无关紧要。
在Helios开发警报机制可能很困难,但借助一些创造性思维和开源协作,我们高效而从容地完成了这项任务。我们利用了OTel和Prometheus,在稳定的周转时间内提供了复杂的警报机制。我们找到了一种关联span和指标的方法,这样当我们获取span并将其转换成指标时,就知道如何将警报重新与业务逻辑联系起来。
但愿这段经历不仅能激励开发者利用开源解决复杂的问题,还能成为我们用户的好伙伴。创新是关键,但除了为了创新而创新之外,我们还希望对用户产生影响,改善他们的体验,希望您也能这样做。
原文标题:How we combined OpenTelemetry traces with Prometheus metrics to build a powerful alerting mechanism,作者:Ran Nozik
责任编辑:华轩 来源: 51CTO 开源Prometheus(责任编辑:探索)
 3月5日,汕尾市金拓新能源有限公司成立,法定代表人为樊鹏,注册资本500万元人民币,经营范围包含:热力生产和供应;发电、输电、供电业务;各类工程建设活动;资源再生利用技术研发;在线能源监测技术研发等。
...[详细]
3月5日,汕尾市金拓新能源有限公司成立,法定代表人为樊鹏,注册资本500万元人民币,经营范围包含:热力生产和供应;发电、输电、供电业务;各类工程建设活动;资源再生利用技术研发;在线能源监测技术研发等。
...[详细] 5月7日上午,南京华贸中心写字楼结构封顶仪式举行,标志着这一江苏省重大项目工程、主城新地标建设接近尾声,即将进入全面招租招商阶段。华贸集团总裁助理、南京分公司总经理郝群、副总经理万旅鹏,中建三局三公司
...[详细]
5月7日上午,南京华贸中心写字楼结构封顶仪式举行,标志着这一江苏省重大项目工程、主城新地标建设接近尾声,即将进入全面招租招商阶段。华贸集团总裁助理、南京分公司总经理郝群、副总经理万旅鹏,中建三局三公司
...[详细] 新浪电影今日12月29日)消息,电影《满江红》发布全新人物海报,解锁双男主沈腾、易烊千玺,领衔主演张译、雷佳音、王佳怡,及主演岳云鹏、潘斌龙、余皑磊“眼神杀”。海报沿用了此前概念海报中劈开织面的设计,
...[详细]
新浪电影今日12月29日)消息,电影《满江红》发布全新人物海报,解锁双男主沈腾、易烊千玺,领衔主演张译、雷佳音、王佳怡,及主演岳云鹏、潘斌龙、余皑磊“眼神杀”。海报沿用了此前概念海报中劈开织面的设计,
...[详细] 1月18日消息,今日贵州西西沃(CC英语)宣布获得阿里系湖畔山南基金A轮战略投资。据悉,CC英语是湖畔山南基金投资的唯一一家线上、线下结合的教育类企业。据创投时报项目数据库,CC英语学校创立于1995
...[详细]
1月18日消息,今日贵州西西沃(CC英语)宣布获得阿里系湖畔山南基金A轮战略投资。据悉,CC英语是湖畔山南基金投资的唯一一家线上、线下结合的教育类企业。据创投时报项目数据库,CC英语学校创立于1995
...[详细]中欧班列(西安)2021年累计运输车数突破3万车 同比增长24.36%
 22日,满载着压缩机、高压隔离开关、汽车配件、自行车等50车货物的X8153次中欧班列(西安),从中国铁路西安局集团有限公司(以下简称“西安局集团公司”)新筑车站驶出,开往霍尔
...[详细]
22日,满载着压缩机、高压隔离开关、汽车配件、自行车等50车货物的X8153次中欧班列(西安),从中国铁路西安局集团有限公司(以下简称“西安局集团公司”)新筑车站驶出,开往霍尔
...[详细] 2017年1月26日消息,法国为网站提供个性化视频推荐的人工智能平台Pulpix宣布获得85万美元Pre-seed轮融资,本次交易的投资方包括Studio VC、Ace Capital、Chon Ta
...[详细]
2017年1月26日消息,法国为网站提供个性化视频推荐的人工智能平台Pulpix宣布获得85万美元Pre-seed轮融资,本次交易的投资方包括Studio VC、Ace Capital、Chon Ta
...[详细]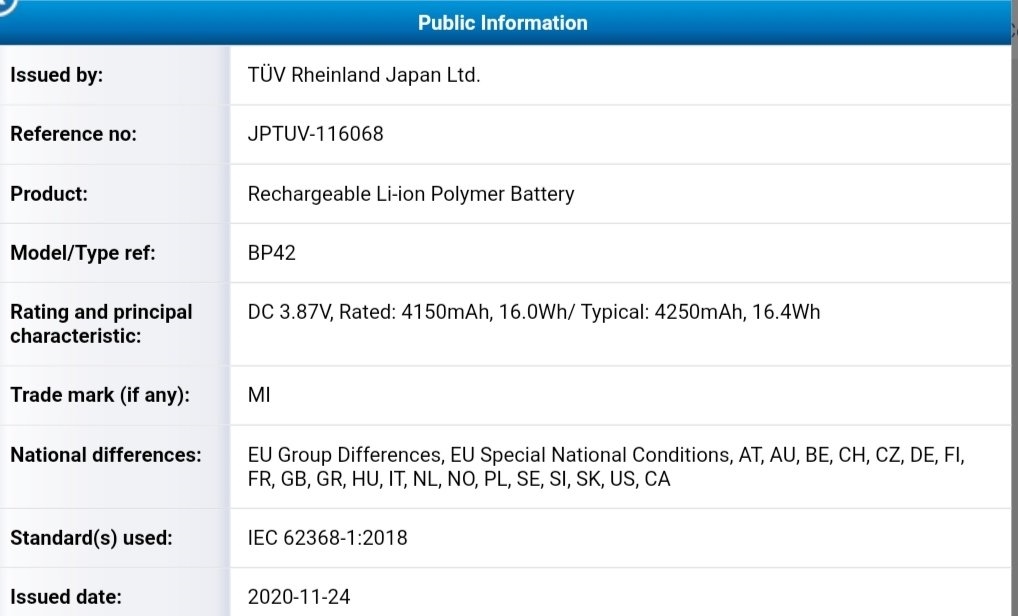 小米11系列近期将登陆全球市场,至少包含两款新机,分别是国内已发售的小米11,以及定位中端的小米11 Lite。从命名来看,小米11 Lite应该是对应青春版,参考前代小米10系列,就曾推出了青春版机
...[详细]
小米11系列近期将登陆全球市场,至少包含两款新机,分别是国内已发售的小米11,以及定位中端的小米11 Lite。从命名来看,小米11 Lite应该是对应青春版,参考前代小米10系列,就曾推出了青春版机
...[详细] 目前国内包括生鲜电商在内的农产品电商接近4000家,其中仅有1%盈利、7%巨额亏损、88%略亏、4%持平,总体上95%的都在赔。根据市场调研机构尼尔森的报告,中国生鲜电子商务市场将在未来三年内呈现爆发
...[详细]
目前国内包括生鲜电商在内的农产品电商接近4000家,其中仅有1%盈利、7%巨额亏损、88%略亏、4%持平,总体上95%的都在赔。根据市场调研机构尼尔森的报告,中国生鲜电子商务市场将在未来三年内呈现爆发
...[详细] 农业银行上班时间农业银行的上班时间如下:1、工作日:上班时间为8:00-17:00,中午照常营业但是会关闭部分窗口;2、双休日及节假日:上班时间为9:30-12:00以及14:30-16:00,中午会
...[详细]
农业银行上班时间农业银行的上班时间如下:1、工作日:上班时间为8:00-17:00,中午照常营业但是会关闭部分窗口;2、双休日及节假日:上班时间为9:30-12:00以及14:30-16:00,中午会
...[详细] 在原有业务发展前景不明及业绩增长乏力的背景下,上市公司往往会通过重组的方式来注入优质资产来实现业绩增长及战略转型。近日,上市公司新能泰山为转变目前经营所遇到的困境,拟注入未来盈利能力强劲的房地产资产,
...[详细]
在原有业务发展前景不明及业绩增长乏力的背景下,上市公司往往会通过重组的方式来注入优质资产来实现业绩增长及战略转型。近日,上市公司新能泰山为转变目前经营所遇到的困境,拟注入未来盈利能力强劲的房地产资产,
...[详细] 开年第一款新机 realme锦鲤手机本月7日发布
开年第一款新机 realme锦鲤手机本月7日发布 《利刃出鞘2》登顶网飞电影播放榜 观看达3500万次
《利刃出鞘2》登顶网飞电影播放榜 观看达3500万次 O2O死亡潮持续发酵: 下一个死的是58到家?
O2O死亡潮持续发酵: 下一个死的是58到家? 塔牌集团(002233.SZ):回购期满 已累计回购股份2871.3526万股
塔牌集团(002233.SZ):回购期满 已累计回购股份2871.3526万股
