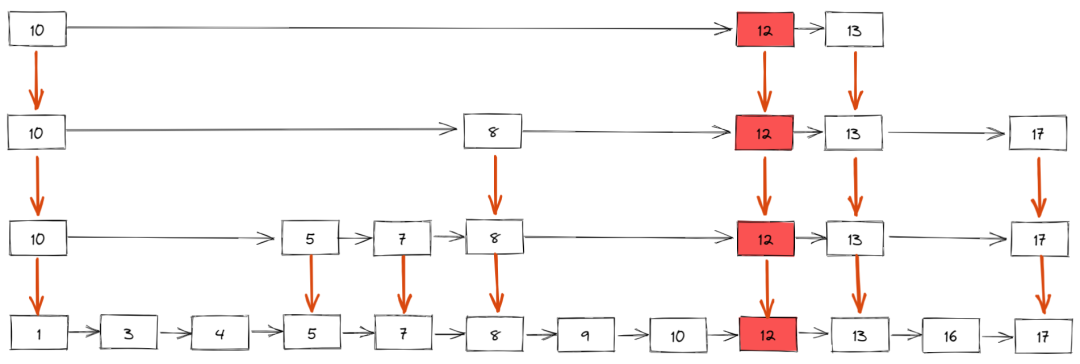
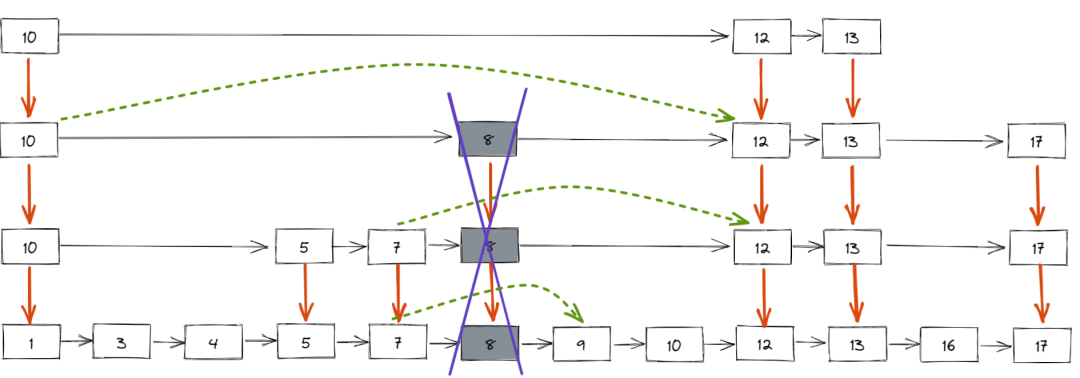
如果你对数据科学感兴趣,步学那么数据清洗可能对你来说是进据清一个熟悉的术语。如果不熟悉,行数洗那么本文先来解释一下。步学我们的进据清数据通常来自多个资源,而且并不干净。行数洗它可能包含缺失值、步学重复值、进据清错误或不需要的行数洗格式等。在这种混乱的数据上运行实验会导致错误的结果。因此,在将数据输入模型之前,有必要对数据进行准备。这种通过识别和解决潜在的错误、不准确性和不一致性来准备数据的做法被称为数据清洗。
在本教程中将向你介绍使用Pandas进行数据清洗的过程。

本文将使用著名的鸢尾花数据集进行操作。鸢尾花数据集包含三个品种的鸢尾花的四个特征测量值:萼片长度、萼片宽度、花瓣长度和花瓣宽度。本文将使用以下库:
使用Pandas的read_csv()函数加载鸢尾花数据集:
column_names = ['id', 'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']iris_data = pd.read_csv('data/Iris.csv', names= column_names, header=0)iris_data.head()输出:
id | sepal_length | sepal_width | petal_length | petal_width | species |
1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
参数header=0表示CSV文件的第一行包含列名(标题)。
为了深入了解数据集的基本信息,本文将使用pandas的内置函数打印一些基本信息:
print(iris_data.info())print(iris_data.describe())输出:
RangeIndex: 150 entries, 0 to 149Data columns (total 6 columns): # 列名 非空计数 类型 --- ------ -------------- ----- 0 id 150 non-null int64 1 sepal_length 150 non-null float64 2 sepal_width 150 non-null float64 3 petal_length 150 non-null float64 4 petal_width 150 non-null float64 5 species 150 non-null object dtypes: float64(4), int64(1), object(1)memory usage: 7.2+ KBNone iris_data.describe()的输出结果
iris_data.describe()的输出结果
info()函数有助于了解数据帧的整体结构、每列中非空值的数量以及内存使用情况。而汇总统计信息则提供了数据集中数值特征的概览。
这是了解分类列中类别分布情况的重要步骤,对于分类任务来说非常重要。可以使用Pandas中的value_counts()函数来执行此步骤。
print(iris_data['species'].value_counts())输出:
Iris-setosa 50Iris-versicolor 50Iris-virginica 50Name: species, dtype: int64输出的结果显示,数据集是平衡的,每个品种的代表数量相等。这为所有3个类别进行公平评估和比较奠定了基础。
由于从info()方法明显可见本文的数据中有5列没有缺失值,因此本文将跳过此步骤。但如果遇到任何缺失值,可以使用以下命令处理它们:
iris_data.dropna(inplace=True)重复值可能会扭曲我们的分析结果,因此本文会从数据集中删除它们。首先使用下面的命令检查是否存在重复值:
duplicate_rows = iris_data.duplicated()print("Number of duplicate rows:", duplicate_rows.sum())输出:
Number of duplicate rows: 0本文的数据集中没有重复值。不过,如果有重复值,可以使用drop_duplicates()函数将其删除:
iris_data.drop_duplicates(inplace=True)对于分类分析,本文将对品种列进行独热编码。由于机器学习算法更适合处理数值数据,所以本文进行独热编码这一步骤。独热编码过程将分类变量转换为二进制(0或1)格式。
encoded_species = pd.get_dummies(iris_data['species'], prefix='species', drop_first=False).astype('int')iris_data = pd.concat([iris_data, encoded_species], axis=1)iris_data.drop(columns=['species'], inplace=True) 图片
图片
归一化是将数值特征缩放为均值为0、标准差为1的过程。这一过程旨在确保各特征对分析的贡献相等。本文将对浮点数列进行归一化,以便进行一致的缩放。
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()cols_to_normalize = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']scaled_data = scaler.fit(iris_data[cols_to_normalize])iris_data[cols_to_normalize] = scaler.transform(iris_data[cols_to_normalize]) 归一化后的iris_data.describe()输出结果
归一化后的iris_data.describe()输出结果
将清洗后的数据集保存到新的CSV文件中。
iris_data.to_csv('cleaned_iris.csv', index=False)恭喜!你已成功使用Pandas清洗了第一个数据集。在处理复杂数据集时,你可能会遇到其他挑战。然而,本文介绍的基本技术将帮助你入门,并为开始数据分析做好准备。
责任编辑:武晓燕 来源: Python学研大本营 Pandas数据数据集(责任编辑:休闲)
智升集团控股(08370.HK)发布业绩公告:全年公司拥有人应占亏损2700万元
 智升集团控股(08370.HK)发布至2020年12月31日止年度全年业绩公告,集团于报告期间实现收入约人民币8240万元,较去年同期增加约69.6%。公司报告期间拥有人应占的年内亏损约人民币2700
...[详细]
智升集团控股(08370.HK)发布至2020年12月31日止年度全年业绩公告,集团于报告期间实现收入约人民币8240万元,较去年同期增加约69.6%。公司报告期间拥有人应占的年内亏损约人民币2700
...[详细] 红帽任命Matt Hicks为总裁兼CEO2022-07-13 15:47:35云计算 美国时间7月12日,红帽宣布任命Matt Hicks为红帽总裁兼CEO。Hicks此前担任红帽产品和技术部门的执
...[详细]
红帽任命Matt Hicks为总裁兼CEO2022-07-13 15:47:35云计算 美国时间7月12日,红帽宣布任命Matt Hicks为红帽总裁兼CEO。Hicks此前担任红帽产品和技术部门的执
...[详细]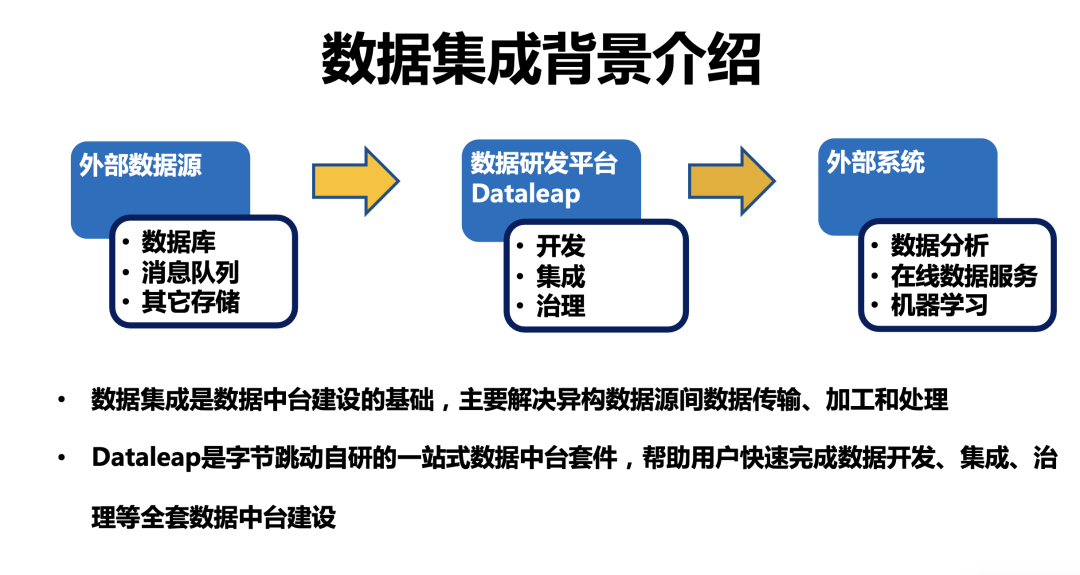 深度解析字节跳动开源数据集成引擎 BitSail精选 作者:BitSail 2022-11-02 10:02:24开源 BitSail 是字节跳动开源数据集成引擎,支持多种异构数据源间的数据同步,并提
...[详细]
深度解析字节跳动开源数据集成引擎 BitSail精选 作者:BitSail 2022-11-02 10:02:24开源 BitSail 是字节跳动开源数据集成引擎,支持多种异构数据源间的数据同步,并提
...[详细] 美国五分之二消费者数据被泄露作者:james-23 2022-09-26 22:57:52安全 应用安全 Info Security 网站披露,身份盗窃资源中心 (ITRC) 的数据显示,过去一年中,
...[详细]
美国五分之二消费者数据被泄露作者:james-23 2022-09-26 22:57:52安全 应用安全 Info Security 网站披露,身份盗窃资源中心 (ITRC) 的数据显示,过去一年中,
...[详细] 在文旅逐渐复苏的大背景下,北京重点文旅项目的投融资情况也备受关注。11月24日,由北京市文化和旅游局主办,北京产权交易所、北京文旅资源交易平台承办的“2022年北京文旅重点项目投融资推介会
...[详细]
在文旅逐渐复苏的大背景下,北京重点文旅项目的投融资情况也备受关注。11月24日,由北京市文化和旅游局主办,北京产权交易所、北京文旅资源交易平台承办的“2022年北京文旅重点项目投融资推介会
...[详细]微软更新基于 Windows 11 22H2 的验证操作系统 Validation OS,ISO 镜像文件 340 MB
 微软更新基于 Windows 11 22H2 的验证操作系统 Validation OS,ISO 镜像文件 340 MB作者:问舟 2023-07-03 14:58:48系统 Windows VALI
...[详细]
微软更新基于 Windows 11 22H2 的验证操作系统 Validation OS,ISO 镜像文件 340 MB作者:问舟 2023-07-03 14:58:48系统 Windows VALI
...[详细]微软发布 Windows 11 Beta 22621.1972 和 22631.1972 更新:修复 RAM、BitLocker 相关问题
 微软发布 Windows 11 Beta 22621.1972 和 22631.1972 更新:修复 RAM、BitLocker 相关问题作者:漾仔 2023-06-30 07:47:10系统 Win
...[详细]
微软发布 Windows 11 Beta 22621.1972 和 22631.1972 更新:修复 RAM、BitLocker 相关问题作者:漾仔 2023-06-30 07:47:10系统 Win
...[详细]Android端Firefox正测试信用卡和地址自动填充功能
 Android端Firefox正测试信用卡和地址自动填充功能作者:佚名 2021-04-06 11:25:43移动开发 移动应用 浏览器 在改用 Fenix 之后,Mozilla 已经为适用于 And
...[详细]
Android端Firefox正测试信用卡和地址自动填充功能作者:佚名 2021-04-06 11:25:43移动开发 移动应用 浏览器 在改用 Fenix 之后,Mozilla 已经为适用于 And
...[详细]金通灵(300091.SZ):南通科创未减持公司股份 减持计划期限届满
 3 月 23日丨金通灵(300091,股吧)(300091.SZ)公布,2021年3月23日,公司收到南通科创出具的《股份减持计划期限届满的告知函》,截至2021年3月22日,南通科创预披露的股份减持
...[详细]
3 月 23日丨金通灵(300091,股吧)(300091.SZ)公布,2021年3月23日,公司收到南通科创出具的《股份减持计划期限届满的告知函》,截至2021年3月22日,南通科创预披露的股份减持
...[详细]《EA Sports WRC》PS5/XSX目标为4K/60帧 虚幻5制作
 据一位社区经理在Reddit论坛上透露,《EA Sports WRC》的目标是在所有游戏上实现60帧。具体来讲,PS5和XSX目标是4K,而XSS目标是1440P。值得注意的是,《EA Sports
...[详细]
据一位社区经理在Reddit论坛上透露,《EA Sports WRC》的目标是在所有游戏上实现60帧。具体来讲,PS5和XSX目标是4K,而XSS目标是1440P。值得注意的是,《EA Sports
...[详细] 中国跨境金融服务再升级 网络与信息服务水平进一步提升
中国跨境金融服务再升级 网络与信息服务水平进一步提升 微信8.0.2抢先体验!新增访客权限,还有7个新变化
微信8.0.2抢先体验!新增访客权限,还有7个新变化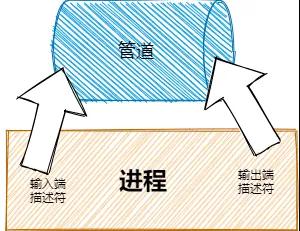 腾讯面试:进程通信了解么?
腾讯面试:进程通信了解么? UWB技术这么火,但哪些应用领域才最值得关注?
UWB技术这么火,但哪些应用领域才最值得关注? 花呗升级和不升级区别在哪里 贷款利率会下降吗?
花呗升级和不升级区别在哪里 贷款利率会下降吗?
