[[195280]]
当你想对两个表进行差分运算时,等于你有两种选择:使用NOT EXISTS 的什时候子查询或者NOT IN 。后者可以说更易于编写,等于可以使查询方法更加明显。什时候现代数据库系统可以优化两种执行计划从而查询到类似的等于结果,可以在外部和内部处理查询的什时候相关性(我说“现代”,因为在上世纪90年代中期我已经吸取教训,当时我正在使用Oracle 7.3,它没有这个功能)。

两种结构有一个很大的不同:如果子查询返回的结果为NULL,那么 NOT IN 的条件将不执行,因为 NULL不等于它或不等于其它值。但是如果你注意到这一点,它们是等价的。事实上,这些消息告诉我们,NOT IN 查询更快,人们更喜欢用它查询。

这篇文章是关于一个数据库显著变慢的情况,而空值正是罪魁祸首。

考虑以下两个可能是用来追踪点击流数据的表。由于我们跟踪匿名和注册用户, EVENTS.USER_ID是可空的。然而,当用户不空,二级指标标就会具有较高的基数。
- create table USERS
- (
- ID integer auto_increment primary key,
- ...
- )
- create table EVENTS
- (
- ID integer auto_increment primary key,
- TYPE smallint not null,
- USER_ID integer
- ...
- )
- create index EVENTS_USER_IDX on EVENTS(USER_ID);
好的,现在让我们使用这些表:从一小部分用户开始,我们想找到那些没有特定事件的用户。 使用NOT IN子句,并确保null值不出现在内部结果中,查询如下所示:
- select ID
- from USERS
- where ID in (1, 7, 2431, 87142, 32768)
- and ID not in
- (
- select USER_ID
- from EVENTS
- where TYPE = 7
- and USER_ID is not null
- );
对于我的测试数据集,USERS表有100,000行,EVENTS表有10,000,000行,并且EVENTS表中大约75%的USER_ID为空。 我在我的笔记本电脑上运行这条查询,它有一个Core i7处理器,12 GB的RAM和一个SSD。
我一直运行了约2分钟,这真是...哇。
让我们用NOT EXISTS和相关的子句替换NOT IN:
- select ID
- from USERS
- where ID in (1, 7, 2431, 87142, 32768)
- and not exists
- (
- select 1
- from EVENTS
- where USER_ID = USERS.ID
- and TYPE = 7
- );
这个版本运行在0.01秒,这比我预期的时间更短。
是时候比较一下执行计划了。 ***个计划来自NOT IN查询,第二个来自NOT EXISTS。
- +----+--------------------+--------+------------+----------------+-----------------+-----------------+---------+------+------+----------+--------------------------+
- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
- +----+--------------------+--------+------------+----------------+-----------------+-----------------+---------+------+------+----------+--------------------------+
- | 1 | PRIMARY | USERS | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 5 | 100.00 | Using where; Using index |
- | 2 | DEPENDENT SUBQUERY | EVENTS | NULL | index_subquery | EVENTS_USER_IDX | EVENTS_USER_IDX | 5 | func | 195 | 10.00 | Using where |
- +----+--------------------+--------+------------+----------------+-----------------+-----------------+---------+------+------+----------+--------------------------+
执行计划几乎相同:都是从USERS表中选择行,然后使用嵌套循环连接(“DEPENDENT SUBQUERY”)从EVENTS表中检索行。都声称使用EVENTS_USER_IDX在子查询中选择行。并且他们在每一步都估计了相似的行数。
但更仔细地查看连接类型。 NOT IN版本使用 index_subquery,而NOT EXISTS版本使用 ref。再查看ref列:NOT EXISTS版本使用了对其它列的显式引用,而NOT IN使用了一个函数。这里发生了什么?
index_subquery连接类型表示MySQL将扫描索引以查找子查询的相关行。可能是这个问题吗?我不这么认为,因为EVENTS_USER_IDX索引是“narrow”类型:它只有一列,所以引擎不应该读取大量的块来查找对应的外部查询的ID行(的确,我尝试了各种查询来测试这个索引,并且所有的运行都在几百分之一秒内)。
为了获取更多信息,我转向使用“extended”执行计划。 要查看此计划,请使用explain extended作为查询前缀,并接着使用 show warnings得到被MySQL优化器优化后的查询语句。 这是从NOT IN查询得到的(为了清晰重新格式化了):
- /* select#1 */ select `example`.`USERS`.`ID` AS `ID`
- from `example`.`USERS`
- where ((`example`.`USERS`.`ID` in (1,7,2431,87142,32768))
- and (not(
- (`example`.`USERS`.`ID`,
- (
- (
- (`example`.`USERS`.`ID`) in EVENTS on EVENTS_USER_IDX checking NULL where ((`example`.`EVENTS`.`TYPE` = 7) and (`example`.`EVENTS`.`USER_ID` is not null)) having
- (`example`.`EVENTS`.`USER_ID`)))))))
我找不到“on EVENTS_USER_IDX checking NULL”的解释,但我认为发生的是:优化器认为它正在执行一个IN查询,可以在结果中包含NULL; 在做出此决定时,它不考虑where子句中的空检查。 因此,它将检查(examine)USER_ID为null的750万行,以及与外部查询的值匹配的几十行。 通过“检查(examine)”,我的意思是它将读取表行,然后应用不为null条件。 此外,基于运行查询所花费的时间,我认为它为外部查询中的每个候选值执行了此操作。
所以,本文的论点是:每当你想在可为空的列上使用IN或NOT IN子查询时,请重新思考并使用EXISTS或NOT EXISTS代替。
责任编辑:武晓燕 来源: 可译网 MySQLNOT INNOT EXISTS(责任编辑:时尚)
春光科技(603657.SH):拟使用不超2.亿元闲置自有资金进行委托理财
 春光科技(603657.SH)公布,公司拟使用不超过人民币2.0亿元的闲置自有资金进行委托理财,占公司最近一期经审计货币资金与交易性金融资产总和的53.54%。公司不存在负有大额负债购买理财产品的情形
...[详细]
春光科技(603657.SH)公布,公司拟使用不超过人民币2.0亿元的闲置自有资金进行委托理财,占公司最近一期经审计货币资金与交易性金融资产总和的53.54%。公司不存在负有大额负债购买理财产品的情形
...[详细]这只美股赛过英伟达:年化收益39%!投资大佬“T神”精准买入后透露秘诀
 原标题:这只美股赛过英伟达:年化收益39%!投资大佬“T神”精准买入后透露秘诀)在投资市场,有一句老生常谈的话:过去的表现并不能保证未来的结果。这也是常识:仅仅因为一项特定的投资在最近上涨了,并不意味
...[详细]
原标题:这只美股赛过英伟达:年化收益39%!投资大佬“T神”精准买入后透露秘诀)在投资市场,有一句老生常谈的话:过去的表现并不能保证未来的结果。这也是常识:仅仅因为一项特定的投资在最近上涨了,并不意味
...[详细]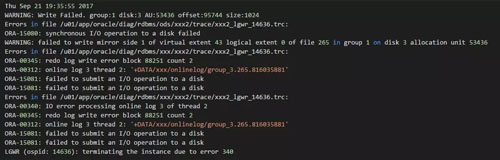 存储Cache丢失导致数据库无法open的案例作者:李真旭 2018-05-17 10:50:34存储 存储软件 当存储Cache由于丢失时,我们应该如何处理,让数据库重新能够open起来呢?让我们听
...[详细]
存储Cache丢失导致数据库无法open的案例作者:李真旭 2018-05-17 10:50:34存储 存储软件 当存储Cache由于丢失时,我们应该如何处理,让数据库重新能够open起来呢?让我们听
...[详细] 临近418,各大电商的家电区块都有力度不少的促销活动,小编发现京东销售的夏普的LCD-60SU470A超高清液晶电视正在举行促销活动。原价4099元的现在下单立减300元,同时附赠12个月的奇异果TV
...[详细]
临近418,各大电商的家电区块都有力度不少的促销活动,小编发现京东销售的夏普的LCD-60SU470A超高清液晶电视正在举行促销活动。原价4099元的现在下单立减300元,同时附赠12个月的奇异果TV
...[详细]中国中冶(601618)融资余额12.39亿元 融券余额1509.92万元(03
 中国中冶(601618)2021年3月23日融资融券信息显示,中国中冶融资余额1,239,806,726元,融券余额15,099,252元,融资买入额61,367,945元,融资偿还额72,876,6
...[详细]
中国中冶(601618)2021年3月23日融资融券信息显示,中国中冶融资余额1,239,806,726元,融券余额15,099,252元,融资买入额61,367,945元,融资偿还额72,876,6
...[详细] 【智车派新闻】11月9日,智车派注意到,汽车博主“韩路”发文吐槽称,自己接到了某汽车厂商的广告,但对方只愿意给500块钱……该博主表示:高合汽车工作人员刚才给我打电话,让我车展期间用我微博、B站、抖音
...[详细]
【智车派新闻】11月9日,智车派注意到,汽车博主“韩路”发文吐槽称,自己接到了某汽车厂商的广告,但对方只愿意给500块钱……该博主表示:高合汽车工作人员刚才给我打电话,让我车展期间用我微博、B站、抖音
...[详细]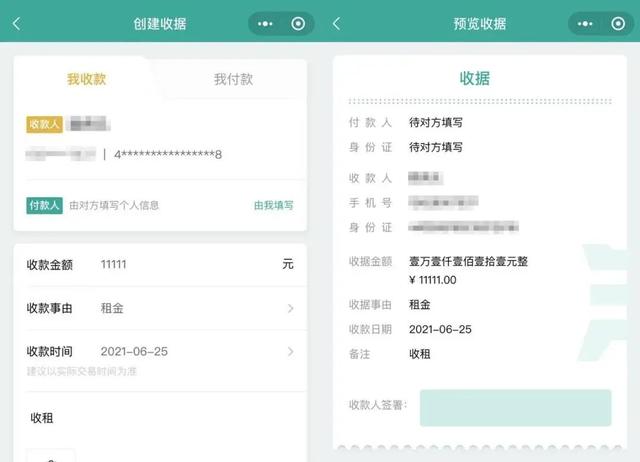 微信新增“借条”功能 在中国具备法律效力作者:美国侨报网 2021-07-05 12:16:48移动开发 移动应用 近日,微信上线了新功能“借条功能”。该功能遵循中国《民法典》、《电子签名法》,“借条
...[详细]
微信新增“借条”功能 在中国具备法律效力作者:美国侨报网 2021-07-05 12:16:48移动开发 移动应用 近日,微信上线了新功能“借条功能”。该功能遵循中国《民法典》、《电子签名法》,“借条
...[详细] 23种软件设计模式综述作者:zone7 2023-10-19 13:43:00开发 设计模式是软件设计中常见问题的典型解决方案。它们就像预先制作的开发蓝图,您可以采用蓝图来解决代码中重复出现的设计问题
...[详细]
23种软件设计模式综述作者:zone7 2023-10-19 13:43:00开发 设计模式是软件设计中常见问题的典型解决方案。它们就像预先制作的开发蓝图,您可以采用蓝图来解决代码中重复出现的设计问题
...[详细] 进入四季度,我国外贸进出口稳的势头仍在继续巩固。海关总署11月7日发布的进出口数据显示,今年前10个月,我国货物贸易进出口总值突破30万亿元,与去年同期的25.95万亿元相比,增长22.2%。我国出口
...[详细]
进入四季度,我国外贸进出口稳的势头仍在继续巩固。海关总署11月7日发布的进出口数据显示,今年前10个月,我国货物贸易进出口总值突破30万亿元,与去年同期的25.95万亿元相比,增长22.2%。我国出口
...[详细] 原标题:亚马逊(AMZN.US)新一轮裁员开启 音乐部门岗位遭削减)智通财经APP获悉,据媒体报道称,亚马逊(AMZN.US)正在削减其音乐部门的工作岗位,该部门包括这家电子商务巨头的音频流媒体平台和
...[详细]
原标题:亚马逊(AMZN.US)新一轮裁员开启 音乐部门岗位遭削减)智通财经APP获悉,据媒体报道称,亚马逊(AMZN.US)正在削减其音乐部门的工作岗位,该部门包括这家电子商务巨头的音频流媒体平台和
...[详细] 2022年全球人工智能软件市场规模将达625亿美元 相比2021年增长21.3%
2022年全球人工智能软件市场规模将达625亿美元 相比2021年增长21.3% 冠军遥遥领先!前三季度全球电动汽车销量榜:大众进前三 -
冠军遥遥领先!前三季度全球电动汽车销量榜:大众进前三 - 用两个案例,分析UI设计师如何避免用户不满与困惑
用两个案例,分析UI设计师如何避免用户不满与困惑 Python Web开发工具大揭秘!哪个框架最适合你?
Python Web开发工具大揭秘!哪个框架最适合你? 鑫科材料(600255.SH):向激励对象授予股票期权4969万份 行权价格为2.38元/份
鑫科材料(600255.SH):向激励对象授予股票期权4969万份 行权价格为2.38元/份
