我们都知道Polars很快,型数但是据库基准最近DuckDB以其独特的数据库特性让我们对他有了更多的关注,本文将对二者进行基准测试,测试评估它们的分析速度、效率和用户友好性。型数


在评测之前我们先看看这两个框架

除此以外还有Pandas、Dask、分析Spark和Vaex本文主要关注DuckDB和Polars的型数基准测试,因为它们特别强调在某些环境下的据库基准速度性能。之所以对这两个框架进行对比是因为 Polars是我目前测试后得到最快的库,而DuckDB它可以更好的支持SQL,这对于我来说是非常好的特这个,因为我更习惯使用SQL来进行查询。

我使用了官方的polar基准测试存储库进行此评估。基准测试由tpc标准化查询组成。这些是专门用来评估实际的、真实的工作流的性能的。在Polars官方网站上,提供了8个此类查询的详细结果。这个基准包含22个唯一的查询(q1、q2等)。这些范围从多表连接到聚合排序,所有这些都是大家认可的经过特殊构建的查询。
测试在一台配备16核AMD vCPU和32GB RAM的机器上进行。所有代码都使用Python 3.10执行。
数据是由使用scale10的存储库代码生成的,下面是每个实体的大小

我们文件读取到内存中,然后进行查询。

在q1、q9、q13和q17中,多连接、基于字符串的过滤和复杂聚合的组合对于polars 来说很难像duckdb那样有效地进行优化。Q21是对惟一值的计数、基于这些计数进行过滤以及随后的一系列连接的操作。
总的来说DuckDB在这两种情况下看起来更快,但这并不是全部。
因为将数据加载到内存中的过程会产生时间和内存开销。我们通过Makefile准确地度量这些成本。
/usr/bin/time -v make run_duckdb /usr/bin/time -v make run_polars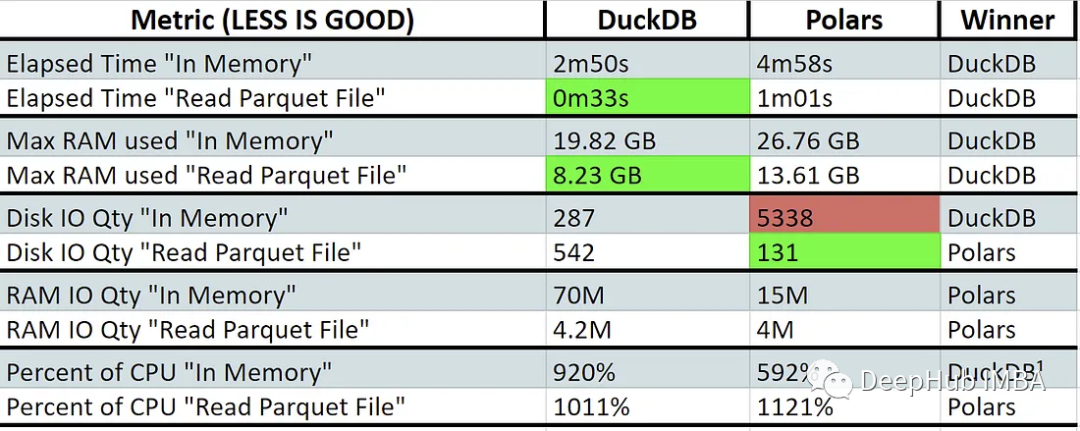
与polar相比,DuckDB在直接读取文件时表现出更快的性能和更低的内存使用。这表明polars 可能使用了交换内存(红色)。这些库不是为跨多台机器扩展而设计的,所以它们都进行了高效CPU核心利用率的设计。
Polars在某些特定领域表现出具有竞争力甚至更好的性能,例如直接读取文件时的磁盘IO和内存操作时的RAM IO。在磁盘IOPS较低的系统中,polar可以表现得更好。
另外:上图中的CPU百分比越高越好。值大于100%表示正在使用多核处理。
下面是我们测试的代码:
DuckDB读取Parquet直接查询
import duckdb conn = duckdb.connect(database=':memory:') df_count = conn.sql(""" SELECT count(*) as count_order FROM 'lineitem.parquet' """ ).fetchdf() print(df_count)DuckDB内存查询
import duckdb conn = duckdb.connect(database=':memory:') conn.sql(""" CREATE TEMP TABLE IF NOT EXISTS lineitem AS SELECT * FROM read_parquet('lineitem.parquet'); """ ) df_count = conn.sql(""" SELECT count(*) as count_order FROM lineitem """ ).fetchdf() print(df_count)Polars 读取Parquet直接查询
import polars as pl df = pl.scan_parquet('lineitem.parquet') df_count = df.select( pl.count().alias("count_order"), ).collect() print(df_count)Polars 内存查询
import polars as pl df = pl.scan_parquet('lineitem.parquet') df = df.collect().rechunk().lazy() df_count = df.select( pl.count().alias("count_order"), ).collect() print(df_count)可以看到在Python处理引擎领域,DuckDB是一个很有前途的竞争者。他在涉及连接和复杂聚合的任务中表现非常亮眼。另外它的简单并且更干净、而且还支持SQL语句直接查询。
但是DuckDB仍处于初级阶段。可能偶尔会遇到bug或缺少功能的问题,如果你有兴趣,可以在你的研究项目中使用DuckDB替代Polars或者Pandas。
本文的测试脚本:
https://github.com/pola-rs/tpch#polars-tpch
责任编辑:华轩 来源: DeepHub IMBA 数据库DuckDB(责任编辑:时尚)
 进入12月,IPO项目的审核工作将陆续开展。根据安排,12月2日将有合富(中国)医疗科技股份有限公司、益方生物科技(上海)股份有限公司(以下简称“益方生物”)在内的8家企业集体
...[详细]
进入12月,IPO项目的审核工作将陆续开展。根据安排,12月2日将有合富(中国)医疗科技股份有限公司、益方生物科技(上海)股份有限公司(以下简称“益方生物”)在内的8家企业集体
...[详细] 物联网连接的未来2023-04-19 11:01:03物联网 物联网的早期涉及的应用只需要连接一段时间来测量库存或打开烤面包机。这些设备以及随后的许多物联网应用,使用最初为手机设计的相同蜂窝技术连接到
...[详细]
物联网连接的未来2023-04-19 11:01:03物联网 物联网的早期涉及的应用只需要连接一段时间来测量库存或打开烤面包机。这些设备以及随后的许多物联网应用,使用最初为手机设计的相同蜂窝技术连接到
...[详细] 9月份Github上Python开源项目排行作者:猿妹整编 2021-10-16 13:32:53开源 PyG (PyTorch Geometric)是一个基于PyTorch构建的库,可轻松编写和训练
...[详细]
9月份Github上Python开源项目排行作者:猿妹整编 2021-10-16 13:32:53开源 PyG (PyTorch Geometric)是一个基于PyTorch构建的库,可轻松编写和训练
...[详细] 【手机中国新闻】10月31日,手机中国注意到,有数码博主曝了一剂猛料,韩国海力士因亏损或将退出传感器领域,而索尼今年业绩很差,压力也空前巨大。有意思的是,早些时候,该博主发文称,手机厂商对豪威的OV5
...[详细]
【手机中国新闻】10月31日,手机中国注意到,有数码博主曝了一剂猛料,韩国海力士因亏损或将退出传感器领域,而索尼今年业绩很差,压力也空前巨大。有意思的是,早些时候,该博主发文称,手机厂商对豪威的OV5
...[详细]鑫科材料(600255.SH):向激励对象授予股票期权4969万份 行权价格为2.38元/份
 鑫科材料(600255.SH)公布,根据《上市公司股权激励管理办法》、《公司2021年股票期权和限制性股票激励计划(草案)》的相关规定及公司2020年年度股东大会的授权,公司董事会认为本次股权激励计划
...[详细]
鑫科材料(600255.SH)公布,根据《上市公司股权激励管理办法》、《公司2021年股票期权和限制性股票激励计划(草案)》的相关规定及公司2020年年度股东大会的授权,公司董事会认为本次股权激励计划
...[详细]偷跑?vivo X100上架京东商城 12GB+256GB售3999元 -
 【手机中国新闻】目前,vivo官方暂未官宣旗下新机vivo X100系列何时发布。10月31日,手机中国注意到,京东商城显示,vivo X100系列已经开启预约,将于今晚八点开启抢购。令人意外的是,新
...[详细]
【手机中国新闻】目前,vivo官方暂未官宣旗下新机vivo X100系列何时发布。10月31日,手机中国注意到,京东商城显示,vivo X100系列已经开启预约,将于今晚八点开启抢购。令人意外的是,新
...[详细] 五个实用的Python编程小技巧作者:学研君 2023-10-26 18:03:14开发 前端 每个元素都有名称,并且可以通过点符号或索引进行访问的元组。可以通过使用namedtuple函数定义一个命
...[详细]
五个实用的Python编程小技巧作者:学研君 2023-10-26 18:03:14开发 前端 每个元素都有名称,并且可以通过点符号或索引进行访问的元组。可以通过使用namedtuple函数定义一个命
...[详细]Docker安装Canal、MySQL 进行简单测试与实现Redis和MySQL 缓存一致性
 Docker安装Canal、MySQL 进行简单测试与实现Redis和MySQL 缓存一致性作者:王振军 2023-02-17 07:54:39数据库 MySQL Canal 是用 Java 开发的基
...[详细]
Docker安装Canal、MySQL 进行简单测试与实现Redis和MySQL 缓存一致性作者:王振军 2023-02-17 07:54:39数据库 MySQL Canal 是用 Java 开发的基
...[详细] 联交所公布,由下周一(22日)起将取消优源国际(02268)的上市地位。联交所指,该公司的股份自2019年8月19日起已暂停买卖。由于该公司未能于今年2月18日或之前履行联交所订下的所有复牌指引并遵守
...[详细]
联交所公布,由下周一(22日)起将取消优源国际(02268)的上市地位。联交所指,该公司的股份自2019年8月19日起已暂停买卖。由于该公司未能于今年2月18日或之前履行联交所订下的所有复牌指引并遵守
...[详细] 端云一体化,极简开发数独闯关游戏元服务作者:Tuer白晓明 2023-08-09 15:01:21系统 OpenHarmony 元服务原名原子化服务)是一种基于HarmonyOS API的全新服务提供
...[详细]
端云一体化,极简开发数独闯关游戏元服务作者:Tuer白晓明 2023-08-09 15:01:21系统 OpenHarmony 元服务原名原子化服务)是一种基于HarmonyOS API的全新服务提供
...[详细] 10月国民经济继续保持恢复态势 保供稳价显效
10月国民经济继续保持恢复态势 保供稳价显效 韦伯望远镜首次检测到恒星合并后的重元素 帮科学家探究生命起源奥秘
韦伯望远镜首次检测到恒星合并后的重元素 帮科学家探究生命起源奥秘 用过 Mongodb 吧, 这三个大坑踩过吗?
用过 Mongodb 吧, 这三个大坑踩过吗? 炸!使用 MyBatis 查询千万数据量?
炸!使用 MyBatis 查询千万数据量? 帅丰电器(605336.SH)拟推176.25万股限制性股票激励计划 授予价格为13.62元/股
帅丰电器(605336.SH)拟推176.25万股限制性股票激励计划 授予价格为13.62元/股