
曾经优化慢查询时,适应索引经常在日志中看到 truncate,哈希当时一直疑惑 truncate 为什么会慢。构造
转到数据库方向之后,适应索引又碰到过几次 truncate 执行时间过长,哈希导致 MySQL 短暂卡住的构造问题。

经过源码分析和同事测试验证,适应索引发现这几次的哈希问题都跟自适应哈希索引有关,所以,构造深入研究下自适应哈希索引就很有必要了。
自适应哈希索引大概会有 3 篇文章。第 1 篇,我们来看看自适应哈希索引的构造过程。
本文基于 MySQL 8.0.32 源码,存储引擎为 InnoDB。
创建测试表:
CREATE TABLE `t1` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `i1` int DEFAULT '0', PRIMARY KEY (`id`) USING BTREE, KEY `idx_i1` (`i1`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3插入测试数据:
INSERT INTO `t1`(`id`, `i1`)VALUES (10, 101), (20, 201), (30, 301);示例 SQL:
SELECT * FROM `t1`WHERE `i1` >= 101 AND `i1` < 301自适应哈希索引,英文全称 Adaptive Hash Index,简称 AHI。
根据上下文需要,后续内容会混用自适应哈希索引和 AHI,不再单独说明。
顾名思义,自适应哈希索引也是一种索引,使用哈希表作为存储结构,自适应的意思是我们无法干涉它的创建、使用、更新、删除,而是由 InnoDB 自行决定什么时候创建、怎么创建、什么时候更新和删除。
我们知道 InnoDB 的主键索引、二级索引都是 B+ 树结构。执行 SQL 语句时,以下几种场景都需要定位到索引叶子结点中的某条记录:
第一条和最后一条记录。第一条记录。得益于多叉结构,B+ 树的层级一般都比较少,通常情况下,从根结点开始,最多经过 3 ~ 4 层就能定位到叶子结点中的记录。
这个定位过程看起来挺快的,单次执行也确实比较快,但是对于频繁执行的场景,还是有一点优化空间的。
为了追求极致性能,InnoDB 实现了 AHI,目的就是能够根据搜索条件直接定位到索引叶子结点中的记录。
 图片
图片
上图是一棵高为 4 的 B+ 树示意图,定位索引叶子结点记录,需要从根结点开始,经过内结点、叶结点,最后定位到记录,路径为:① -> ② -> ③ -> ④
 图片
图片
AHI 会使用多个 hash 桶来存储哈希值到记录地址的映射,上图是一个 hash 桶的示意图。
橙色块表示记录地址组成的链表,因为多条记录可能被映射到 hash 桶中的同一个位置。
AHI 定位一条记录时,根据 where 条件中的某些字段计算出哈希值,然后直接到 hash 桶中找到对应的记录。
如果多条记录被映射到 hash 桶中的同一个位置,那么找到的是个链表,需要遍历这个链表以找到目标记录。
AHI 能提升定位记录的效率,但是,有得到必然有付出,天上掉馅饼的事在计算机世界里是不会发生的。
为了简洁,这里我们把定位索引叶子结点中的记录简称为定位记录,后面内容也依此定义,不再单独说明。
高效定位记录,付出的代价是存储哈希值到记录地址的映射占用的内存空间、以及构造映射花费的时间。
因为有时间、空间成本,所以,InnoDB 希望构造 AHI 之后,能够尽可能多的用上,做到收益大于成本。直白点说,就是需要满足一定的条件,才能构造 AHI。
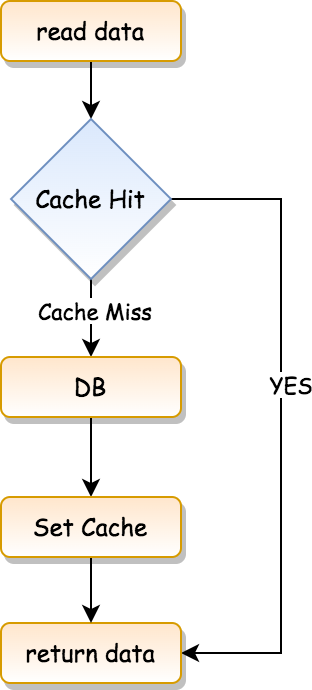
AHI 采用的是组团构造逻辑,也就是以数据页为单位,满足一定条件之后,就会为数据页中的所有记录构造 AHI,主要流程如下:
 图片
图片
第 1 步,为数据页所属的索引计数(index->search_info->hash_analysis)。
SQL 执行过程中,每次定位某个索引叶子结点中的记录,该索引的计数都会加 1。
如果索引计数达到 17,进入第 2 步,否则,执行流程到此结束。
因为第 2、3 步为构造信息计数、为数据页计数也是需要时间成本的,所以,这里设置了第 1 道槛,只有索引被使用一定次数之后,才会执行第 2、3 步。
第 2 步,为构造信息计数(index->search_info->n_hash_potential)。
对于 select、insert、update、delete,定位记录时,搜索条件和叶子结点中的记录比较,会产生两个边界,左边为下界,右边为上界,基于下界和上界可以得到用于构造 AHI 的信息,我们称之为构造信息。
 图片
图片
以上是定位记录时产生的下界、上界示意图。定位记录过程中,下界和上界会不断向目标记录靠近,最终,下界或上界的其中一个会指向目标记录。
如果某次定位记录时,基于下界或上界得到的构造信息,和索引对象中保存的构造信息一致,该构造信息计数加 1。否则,该索引计数清零,构造信息计数清零或重置为 1(具体见下一小节的介绍)。
第 3 步,为数据页计数(block->n_hash_helps)。
定位到索引叶子结点记录之后,就知道了该记录所属的数据页,如果本次得到的构造信息和数据页对象中保存的构造信息相同,数据页计数加 1,否则数据页计数重置为 1。
第 4 步,为数据页构造 AHI。
如果满足以下两个条件,第 3 步的数据页就具备了构造 AHI 的资格:
具备构造 AHI 的资格之后,对于以下三种情况之一,会为数据页构造 AHI:
注意:从各个条件判断,到最终构造 AHI 的整个流程,并不是在执行一条 SQL 的过程中完成的,而是在执行多条 SQL 的过程中完成的。
到这里,构造 AHI 的主要流程就介绍完了,构造过程的具体细节,请继续往下看。
定位记录会调用 btr_cur_search_to_nth_level(),这也是 AHI 的构造入口:
// storage/innobase/btr/btr0cur.ccvoid btr_cur_search_to_nth_level(...) { ... if (btr_search_enabled && !index->disable_ahi) { // AHI 的构造入口 btr_search_info_update(cursor); } ...}btr_search_enabled = true(默认值),表示 InnoDB 启用了 AHI。
!index->disable_ahi = true,即 index->disable_ahi = false,表示 index 对应的索引没有禁用 AHI。
只有内部临时表、没有主键的表禁用了 AHI。
也就是说,对于正常的用户表、系统表,!index->disable_ahi = true,会调用 btr_search_info_update(),进入 AHI 的构造流程。
构造 AHI 的第 1 步,就是调用 btr_search_info_update() 进行索引计数。
// storage/innobase/include/btr0sea.icstatic inline void btr_search_info_update(btr_cur_t *cursor) { const auto index = cursor->index; ... // 索引计数加 1 const auto hash_analysis_value = ++index->search_info->hash_analysis; // BTR_SEARCH_HASH_ANALYSIS = 17(硬编码) if (hash_analysis_value < BTR_SEARCH_HASH_ANALYSIS) { /* Do nothing */ return; } ... btr_search_info_update_slow(cursor);}btr_search_info_update() 每次被调用都会增加索引计数(++index->search_info->hash_analysis)。
自增之后,如果索引计数小于 17,不需要进入 AHI 构造流程的下一步,直接返回。
如果索引计数大于等于 17,调用 btr_search_info_update_slow(),进入 AHI 构造流程的下一步。
看到这里,大家是否会有疑问:对于一条能使用索引的 select 语句,如果 where 条件只有一个扫描区间,执行过程中,btr_search_info_update() 最多会被调用几次?
我们通过 1. 准备工作小节的示例 SQL 来揭晓答案,SQL 如下:
SELECT * FROM `t1`WHERE `i1` >= 101 AND `i1` < 301执行计划如下:
 图片
图片
通过执行计划可知,示例 SQL 执行过程中,会使用索引 idx_i1。
查询优化阶段,MySQL 需要定位到扫描区间的第一条和最后一条记录,用于计算扫描区间覆盖的记录数量:
查询执行阶段,从存储引擎读取第一条记录之前,需要定位扫描区间的第一条记录,即满足 id >= 101 的第一条记录,第 3 次调用 btr_cur_search_to_nth_level()。
定位扫描区间的第一条和最后一条记录,都是定位索引叶子结点中的记录。
到这里,我们就得到了前面那个问题的答案:3 次。
如果某个索引的计数达到了 17,就会进入 AHI 构造流程的第 2 步,根据本次定位记录过程中得到的下界和上界,确定使用索引的前几个字段构造 AHI,以及对于索引中前几个字段值相同的一组记录,构造 AHI 时选择这组记录的第一条还是最后一条。
3.原理介绍小节的第 2 步,我们已经把这些信息命名为构造信息。
基于定位记录时得到的下界和上界确定构造信息、为构造信息计数的逻辑由 btr_search_info_update_hash() 完成。
// storage/innobase/btr/btr0sea.ccvoid btr_search_info_update_slow(btr_cur_t *cursor) { ... const auto block = btr_cur_get_block(cursor); ... btr_search_info_update_hash(cursor); ...}btr_search_info_update_hash() 的代码有点长,我们分 2 段介绍。
介绍第 1 段代码之前,我们先来看看表示构造信息的结构体定义(index->search_info->prefix_info):
// storage/innobase/include/buf0buf.h// 为了方便阅读,以下结构体定义对源码做了删减struct btr_search_prefix_info_t { /** recommended prefix: number of bytes in an incomplete field */ uint32_t n_bytes; /** recommended prefix length for hash search: number of full fields */ uint16_t n_fields; /** true or false, depending on whether the leftmost record of several records with the same prefix should be indexed in the hash index */ bool left_side;}btr_search_prefix_info_t 包含 3 个属性:
接下来,我们开始介绍 btr_search_info_update_hash() 的第 1 段代码逻辑。
// storage/innobase/btr/btr0sea.cc/(责任编辑:知识)
中证金力挺民企债券融资专项计划 完善民营企业债券融资支持机制
 民企债券融资迎来重要支持方案。证监会11日晚称,交易所债券市场推出民营企业债券融资专项支持计划,以稳定和促进民营企业债券融资。中证金正是大名鼎鼎的国家队,成立于2011年10月,2015年市场大幅波动
...[详细]
民企债券融资迎来重要支持方案。证监会11日晚称,交易所债券市场推出民营企业债券融资专项支持计划,以稳定和促进民营企业债券融资。中证金正是大名鼎鼎的国家队,成立于2011年10月,2015年市场大幅波动
...[详细]十一月金融数据回暖 较去年同期有所改善 逆周期调控效果逐步显现
 中国人民银行10日公布的数据显示,在经历了10月的回落后,11月金融数据回暖。在人民币贷款方面,11月,人民币贷款增加1.39万亿元,同比多增1387亿元。分部门看,住户部门贷款增加6831亿元,其中
...[详细]
中国人民银行10日公布的数据显示,在经历了10月的回落后,11月金融数据回暖。在人民币贷款方面,11月,人民币贷款增加1.39万亿元,同比多增1387亿元。分部门看,住户部门贷款增加6831亿元,其中
...[详细] A股上市公司半年报披露接近尾声。数据显示,上半年受疫情、水灾、外部环境变化等不利因素影响,A股上市公司业绩整体出现下滑。尽管如此,仍然有近半数上市公司净利润实现逆势增长,科创板表现强劲,中小板和创业板
...[详细]
A股上市公司半年报披露接近尾声。数据显示,上半年受疫情、水灾、外部环境变化等不利因素影响,A股上市公司业绩整体出现下滑。尽管如此,仍然有近半数上市公司净利润实现逆势增长,科创板表现强劲,中小板和创业板
...[详细]《中国县域经济发展报告2019》发布 房地产开发投资增速上涨
 12月6日,《中国县域经济发展报告2019》暨全国百强县(区)报告在北京发布。该报告由中国社会科学院财经战略研究院县域经济课题组完成。据课题组组长吕风勇介绍,报告原则上根据地区生产总值、地方公共财政收
...[详细]
12月6日,《中国县域经济发展报告2019》暨全国百强县(区)报告在北京发布。该报告由中国社会科学院财经战略研究院县域经济课题组完成。据课题组组长吕风勇介绍,报告原则上根据地区生产总值、地方公共财政收
...[详细] 联交所公布,由下周一(22日)起将取消优源国际(02268)的上市地位。联交所指,该公司的股份自2019年8月19日起已暂停买卖。由于该公司未能于今年2月18日或之前履行联交所订下的所有复牌指引并遵守
...[详细]
联交所公布,由下周一(22日)起将取消优源国际(02268)的上市地位。联交所指,该公司的股份自2019年8月19日起已暂停买卖。由于该公司未能于今年2月18日或之前履行联交所订下的所有复牌指引并遵守
...[详细] 黄金首饰戴久了,难免会有污渍。清洗黄金首饰本来是一件普通的事,但泰州兴化市钓鱼镇的王奶奶却在清洗后,悔不当初。原来,王奶奶遇到了专门以清洗黄金首饰为名的窃贼,她 42 克的金手镯洗完只剩 22 克,但
...[详细]
黄金首饰戴久了,难免会有污渍。清洗黄金首饰本来是一件普通的事,但泰州兴化市钓鱼镇的王奶奶却在清洗后,悔不当初。原来,王奶奶遇到了专门以清洗黄金首饰为名的窃贼,她 42 克的金手镯洗完只剩 22 克,但
...[详细]前11个月我国货物贸易进出口总值28.5万亿元 比去年同期增长2.4%
 12月8日,中国海关总署发布数据显示,据海关统计,今年前11个月,我国货物贸易进出口总值28.5万亿元,比去年同期(下同)增长2.4%。其中,出口15.55万亿元,增长4.5%;进口12.95万亿元,
...[详细]
12月8日,中国海关总署发布数据显示,据海关统计,今年前11个月,我国货物贸易进出口总值28.5万亿元,比去年同期(下同)增长2.4%。其中,出口15.55万亿元,增长4.5%;进口12.95万亿元,
...[详细]江西发改委召开调度会了解江西省国家新型城镇化综合试点工作进展情况
 8月25日,江西发改委召开国家新型城镇化综合试点工作调度会,调度了解我省国家新型城镇化综合试点工作进展情况,交流试点工作经验做法,研究解决试点工作中存在的困难问题,推动试点工作取得实效。会上,鹰潭市、
...[详细]
8月25日,江西发改委召开国家新型城镇化综合试点工作调度会,调度了解我省国家新型城镇化综合试点工作进展情况,交流试点工作经验做法,研究解决试点工作中存在的困难问题,推动试点工作取得实效。会上,鹰潭市、
...[详细]兴达国际(01899.HK)发布公告:预期2020年纯利同比减少50%
 兴达国际(01899.HK)公告,集团预期截至2020年12月31日止年度公司拥有人应占纯利将较截至2019年12月31日止年度录得50%至60%的下跌。董事会认为该减少乃主要由于确认以股份为基础的付
...[详细]
兴达国际(01899.HK)公告,集团预期截至2020年12月31日止年度公司拥有人应占纯利将较截至2019年12月31日止年度录得50%至60%的下跌。董事会认为该减少乃主要由于确认以股份为基础的付
...[详细] 3月21日,*ST华泽(9.680,-0.51,-5.00%)股票在停牌逾2年后复牌交易。至3月26日,*ST华泽的股价每天均为“一”字跌停。而据华商基金公司对其估值的0.55
...[详细]
3月21日,*ST华泽(9.680,-0.51,-5.00%)股票在停牌逾2年后复牌交易。至3月26日,*ST华泽的股价每天均为“一”字跌停。而据华商基金公司对其估值的0.55
...[详细] 皇朝家居(01198.HK)发布公告:年度归母净利同比下降89.2%
皇朝家居(01198.HK)发布公告:年度归母净利同比下降89.2% 上市公司半年报成绩单出炉 逾八成企业上半年实现盈利
上市公司半年报成绩单出炉 逾八成企业上半年实现盈利 “双焦”联袂演绎V型走势 提涨计划或将持续支撑期价
“双焦”联袂演绎V型走势 提涨计划或将持续支撑期价 安徽淮北市财政局三举措加强预算单位银行账户管理 预防和治理腐败
安徽淮北市财政局三举措加强预算单位银行账户管理 预防和治理腐败 江西省一季度国有经济亮出成绩单 国有企业资产规模达到6.1万亿元
江西省一季度国有经济亮出成绩单 国有企业资产规模达到6.1万亿元
