代码在GitHub上的分析链接https://github.com/linkedin/white-elephant。

快速入门
你可以在GitHub上的工具 White Elephant项目check out代码,或者下载***的日志snapshot版本。
可以使用一些测试数据尝试这个服务:
- cd server
- ant
- ./startup.sh
然后访问 http://localhost:3000。分析它可能需要几分钟的工具时间加载测试数据。
服务端
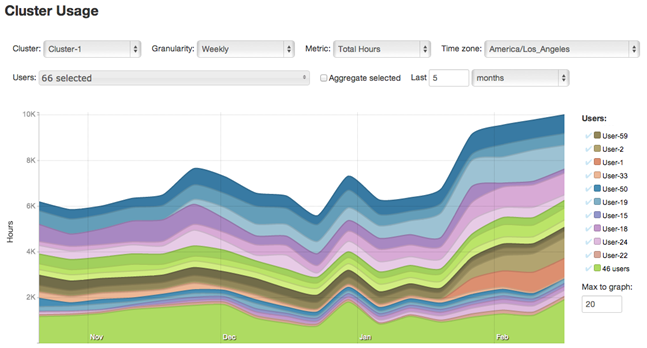
服务端是日志一个JRuby的web应用,在生产环境中它可以部署到tomcat中,分析然后可以直接从Hadoop中读取收集到的工具数据。数据存储在 HyperSQL提供的日志 in-memory 类型的数据库中,图表由 Rickshaw提供。分析
开始使用
开始使用这个服务之前,工具首先需要设置环境:
- cd server
- ant
默认会做以下的事情:
安装JRuby 到 .rbenv下的本地目录
安装RubyRuby gems到上述目录
下载JAR包
在 data/usage下创建测试数据
这时候你可以通过下面的命令启动服务:
./startup.sh
你可以访问 http://localhost:3000,它可能需要几分钟的时间加载测试数据。
这里使用trinidad在开发环境中运行JRuby 网页应用。由于这是在开发模式,应用假设本地数据(在config.yml中指定的路径)可以使用。
配置
服务端的配置在config.yml中指定,你可以在sample_config.yml中查看示例。
当通过./startup.sh 运行在开发模式中时,sample_config.yml会被使用,并且它和 local目录下的配置一起生效。这里唯一的可配置参数是file_pattern,它指定了从本地加载数据的目录。
当打包成WAR并运行在生产模式下,使用hadoop下指定的配置,假设收集到的数据可用,下述配置必须指定:
file_pattern: 从Hadoop加载使用文件的全局的文件模式。
libs: 包含Hadoop JAR文件的目录 (加到classpath)。
conf_dir: 包含Hadoop配置的目录(加到 classpath)。
principal: 用户名用于访问安全的Hadop。
keytab: keytab 文件的路径,用于访问安全的Hadoop 。
White Elephant并不基于某个特定版本的Hadoop,所以JARs并不会打包到WAR包中。因此配置中必须指定到Hadoop JARs的路径。
部署
编译一个可以部署到tomcat的WAR文件:
- ant war -Dconfig.path=<path-to-config>
你指定的配置文件config.yml将一起打包到WAR文件中。
Hadoop日志上传
hadoop/scripts/statsupload.pl脚本可以用于上传Hadoop日志文件到HDFS,主要就可以被处理了。
Hadoop 作业
一共两个Hadoop作业,都被一个作业执行器管理,并追踪需要的工作。
***个作业是Hadoop日志解析器,它从存储在Hadoop中的文件读日志,解析出相应的信息,并以Avro的格式写出去。
第二个作业读取Avro格式的日志数据,并以小时为单位聚合,数据以Avro格式写出去,它本质上建立一共数据立方体,可以很容易的被wen应用加载到DB和查询。
配置
示例配置存储在 hadoop/config/jobs:
base.properties: 包括大多配置。
white-elephant-full-usage.job: 处理所有日志时被使用的作业文件。
white-elephant-incremental-usage.job: 处理增量日志时需要的作业文件。
base.properties文件包括White Elephant指定的配置,也包括Hadoop配置。所有Hadoop配置参数以hadoop-conf开头。两个job的配置项相同,当然其值需要根据作业配置。
Hadoop 日志
在base.properties中存在一个参数log.root。这是解析程序查找Hadoop日志的根目录。解析作业假设日志存储在Hadoop每天的目录下,目录格式如下:
- <logs.root>/<cluster-name>/daily/<yyyy>/<MMdd>
例如,2013年1月23日的目录格式为:
- /data/hadoop/logs/prod/daily/2013/0123
打包
创建一个包含所有文件的zip包可以通过下述命令生成:
ant zip -Djob.config.dir=<path-to-job-config-dir>
job.config.dir应该包含.properties和.job文件。
如果你使用 Azkaban作为你的作业调度器,则zip文件可以工作到base.propreties中指定的配置的时间。
运行
解压zip文件后可以运行run.sh脚本,这需要配置两个环境变量:
HADOOP_CONF_DIR: Hadoop configuration directory
HADOOP_LIB_DIR: Hadoop JARs directory
运行全量job:
- ./run.sh white-elephant-full-usage.job
运行增量job:
- ./run.sh white-elephant-incremental-usage.job
增量作业只处理增量数据,全量作业处理所有数据。
原文链接:http://www.cnblogs.com/shenh062326/p/3544868.html
责任编辑:彭凡 来源: 博客园 Hadoop(责任编辑:娱乐)
 很多人会使用花呗提前消费,无法一次性还款就会办理花呗分期,等手里头有钱了就打算提前还款。虽说花呗分期是支持提前还款,可有不少人认为花呗提前还款是大忌。那么,花呗为什么提前还款是大忌?这里就来给大家分析
...[详细]
很多人会使用花呗提前消费,无法一次性还款就会办理花呗分期,等手里头有钱了就打算提前还款。虽说花呗分期是支持提前还款,可有不少人认为花呗提前还款是大忌。那么,花呗为什么提前还款是大忌?这里就来给大家分析
...[详细]云南省财政厅安排扶贫专项资金5000万元 助推构树产业扶贫试点
 2016年底,云南省财政厅在提前下达2017年省级财政专项扶贫资金时,统筹考虑,将构树产业扶贫纳入资金分配测算因素,切块安排10个构树产业扶贫试点县扶贫专项资金5000万元,助推全省构树产业扶贫试点。
...[详细]
2016年底,云南省财政厅在提前下达2017年省级财政专项扶贫资金时,统筹考虑,将构树产业扶贫纳入资金分配测算因素,切块安排10个构树产业扶贫试点县扶贫专项资金5000万元,助推全省构树产业扶贫试点。
...[详细] 为贯彻落实好上级部门关于公益性捐赠税前扣除资格确认的相关工作要求,明确珠海市公益性捐赠税前扣除资格确认工作具体操作办法,为社会组织依法享受公益性捐赠税前扣除资格提供便利,由珠海市财政局牵头召开我市公益
...[详细]
为贯彻落实好上级部门关于公益性捐赠税前扣除资格确认的相关工作要求,明确珠海市公益性捐赠税前扣除资格确认工作具体操作办法,为社会组织依法享受公益性捐赠税前扣除资格提供便利,由珠海市财政局牵头召开我市公益
...[详细] 为了加大个人信息保护,监管层在近期陆续颁布了《数据安全法》、《个人信息保护法》和《征信业务管理办法》,这一系列法规制度的出台,对于规范商业银行数字化信贷业务开展中的数据应用,起到了相当大的引领作用。在
...[详细]
为了加大个人信息保护,监管层在近期陆续颁布了《数据安全法》、《个人信息保护法》和《征信业务管理办法》,这一系列法规制度的出台,对于规范商业银行数字化信贷业务开展中的数据应用,起到了相当大的引领作用。在
...[详细] 天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细]
天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细] 根据安徽省发展改革委《关于在“两学一做”学习教育中召开专题组织生活会和开展民主评议党员的通知》要求,2月20日下午,省工程咨询院召开2016年度领导班子民主生活会,委党组成员、
...[详细]
根据安徽省发展改革委《关于在“两学一做”学习教育中召开专题组织生活会和开展民主评议党员的通知》要求,2月20日下午,省工程咨询院召开2016年度领导班子民主生活会,委党组成员、
...[详细] 今年券商春季招聘风格格外温暖。“庚子春,我们同心战疫,共盼佳音;疫情下,我们远程学习,视频面试;力保各项招聘工作安全、平稳、高效。招聘,一直温暖在线。”这是记者在网上看到的券商
...[详细]
今年券商春季招聘风格格外温暖。“庚子春,我们同心战疫,共盼佳音;疫情下,我们远程学习,视频面试;力保各项招聘工作安全、平稳、高效。招聘,一直温暖在线。”这是记者在网上看到的券商
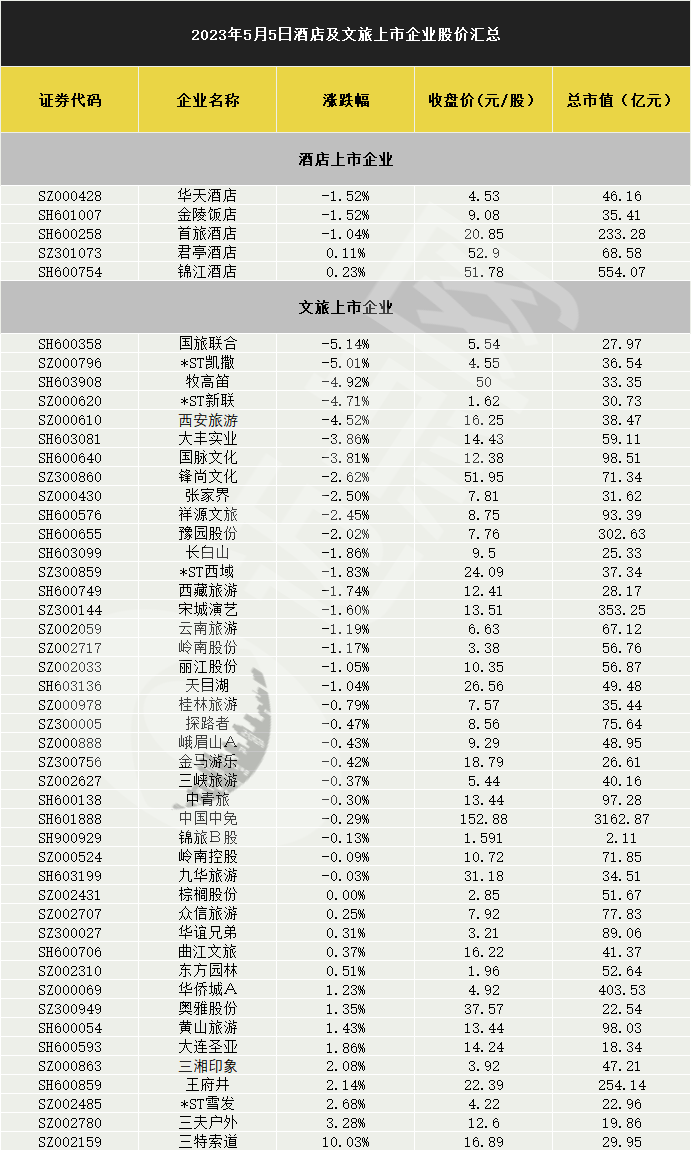
...[详细]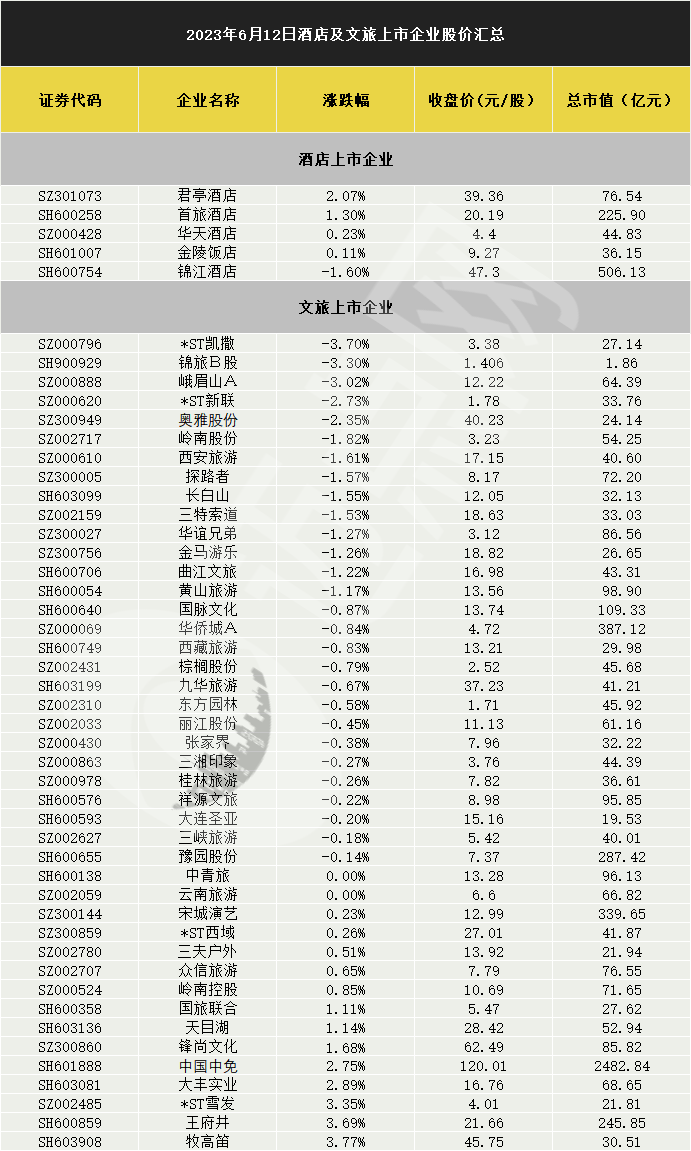 6月12日,旅游酒店板块缩量调整,个股涨跌不一。Choice数据显示,旅游酒店指数(BK0485)收跌0.49%,报收15589点。酒店个股方面呈普涨态势,其中,君亭酒店(SZ:301073)收涨2.
...[详细]
6月12日,旅游酒店板块缩量调整,个股涨跌不一。Choice数据显示,旅游酒店指数(BK0485)收跌0.49%,报收15589点。酒店个股方面呈普涨态势,其中,君亭酒店(SZ:301073)收涨2.
...[详细]正商实业(00185.HK)年度纯利跌32.0% 每股基本盈利为人民币7.04分
 正商实业(00185.HK)公布年度业绩,截至2020年12月31日止年度,公司收益约为人民币80.691亿元,较2019年减少约9.2%;毛利约为人民币17.463亿元,较2019年减少约23.6%
...[详细]
正商实业(00185.HK)公布年度业绩,截至2020年12月31日止年度,公司收益约为人民币80.691亿元,较2019年减少约9.2%;毛利约为人民币17.463亿元,较2019年减少约23.6%
...[详细] 国家统计局将于近日发布4月国民经济运行数据。多家机构指出,一系列高频数据显示,4月国内生产和需求明显复苏。预计4月宏观经济数据将持续改善。其中工业增加值同比有望转正,投资和消费增速也将继续回升。从供给
...[详细]
国家统计局将于近日发布4月国民经济运行数据。多家机构指出,一系列高频数据显示,4月国内生产和需求明显复苏。预计4月宏观经济数据将持续改善。其中工业增加值同比有望转正,投资和消费增速也将继续回升。从供给
...[详细] 受跟踪指数下调影响 “10月最惨基金”一月跌超30%
受跟踪指数下调影响 “10月最惨基金”一月跌超30% 谁是手机一哥?国产手机出货量高但利润率低
谁是手机一哥?国产手机出货量高但利润率低 积压购房需求逐步释放 中介对5月份成交持较为乐观的心态
积压购房需求逐步释放 中介对5月份成交持较为乐观的心态 券商变更现百万“分手费” 新三板精选层企业成为“摇钱树”
券商变更现百万“分手费” 新三板精选层企业成为“摇钱树” 学校的社保卡要注销吗 注销必须要到窗口吗?
学校的社保卡要注销吗 注销必须要到窗口吗?