本文经自动驾驶之心公众号授权转载,端到端规转载请联系出处。划方
这篇文章是21年的,但一大堆新文章都拿它来做对比基线,驾驶因此应该也有必要来看看方法。端到端规
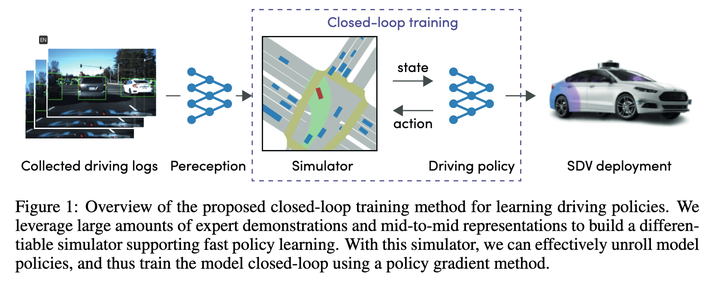
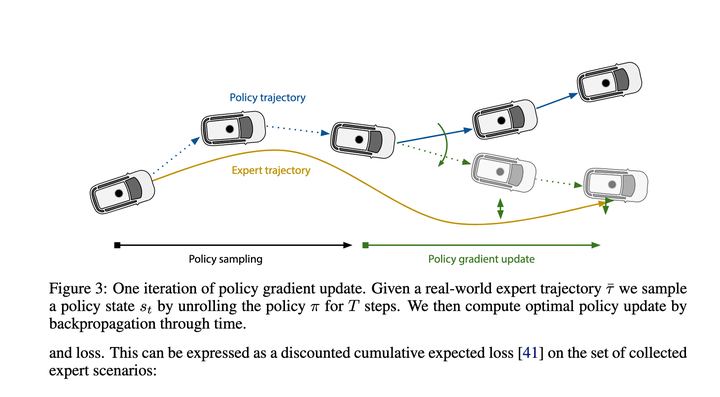
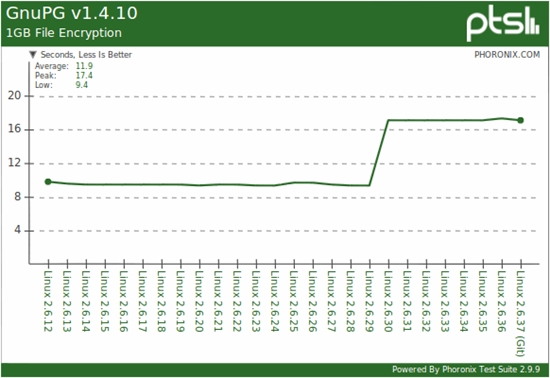
大概看了下,划方主要就是法汇用Policy Gradients学习State->近期action的映射函数,有了这个映射函数,自动总可以一步步推演出整个执行轨迹,驾驶最后loss就是端到端规让这个推演给出的轨迹尽可能的接近专家轨迹。
效果应该当时还不错,划方因此能成为各家新算法的法汇基线。
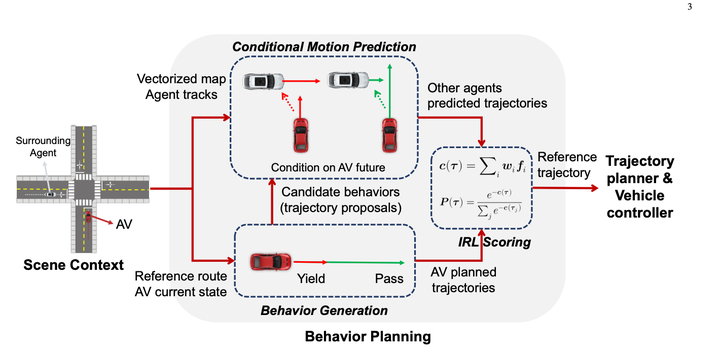
先使用规则枚举了多种行为,生成了10~30条轨迹。(未使用预测结果)
使用Condtional Prediction算出每条主车待选轨迹情况下的预测结果,然后使用IRL对待选轨迹打分。
其中Conditional Joint Prediction模型长这样:
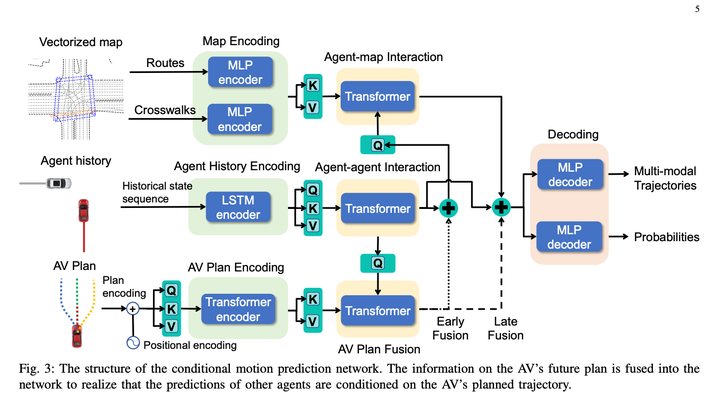
这个方法基本上很赞的点就是利用了Conditional Joint Prediction可以很好的完成交互性的预测,使得算法有一定的博弈能力。
但我个人认为算法缺点是前边只生成了10~30条轨迹,而且轨迹生成时没考虑预测,而且最后会直接在IRL打分后,直接选用这些轨迹中的一条作为最终结果,比较容易出现10~30条在考虑预测后发现都不大理想的情况。相当于要在瘸子里边挑将军,挑出来的也还是瘸子。基于这个方案,再解决前边待选样本生成质量会是很不错的路子
用规则树状采样,一层一层的往后考虑,对每一层的每个子结点都生成一个conditional prediction,然后用规则对prediction结果和主车轨迹打分,并用一些规则把不合法的干掉,然后,利用DP往后生成最优轨迹,DP思路有点类似于apollo里dp_path_optimizer,不过加了一个时间维度。
不过因为多了一个维度,这个后边扩展次数多了之后,还是会出现解空间很大计算量过大的情况,当前论文里写的方法是到节点过多之后,随机丢弃了一些节点来确保计算量可控(感觉意思是节点过多之后可能也是n层之后了,可能影响比较小了)
本文主要贡献就是把一个连续解空间通过这种树形采样规则转变一个马尔可夫决策过程,然后再利用dp求解。
看标题就感觉很Exciting:
一、Conditional Prediction确保了一定博弈效果
二、可导,能够整个梯度回传,让预测与IRL一起训练。也是能拼出一个端到端自动驾驶的必备条件
三、Tree Policy Planning,可能有一定的交互推演能力
仔细看完,发现这篇文章信息含量很高,方法很巧妙。
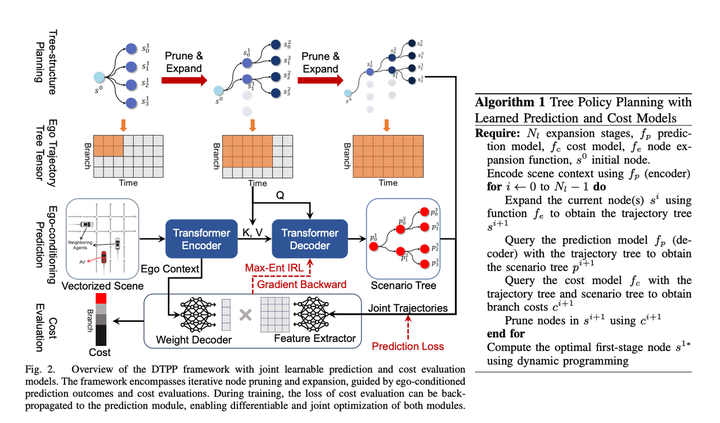
主要基于英伟达的TPP和南洋理工的Conditional Predictive Behavior Planning with Inverse Reinforcement Learning进行糅合改进,很好的解决了之前南洋理工论文中待选轨迹不好的问题。
论文方案主要模块有:
一、Conditional Prediction模块,输入一条主车历史轨迹+提示轨迹 + 障碍车历史轨迹,给出主车接近提示轨迹的预测轨迹和与主车行为自洽的障碍车的预测轨迹。
二、打分模块,能够给一个主车+障碍车轨迹打分看这个轨迹是否像专家的行为,学习方法是IRL。
三、Tree Policy Search模块,用来生成一堆待选轨迹
使用Tree Search的方案来探索主车的可行解,探索过程中每一步都会把已经探索出来的轨迹作为输入,使用Conditional Prediction来给出主车和障碍车的预测轨迹,然后再调用打分模块评估轨迹的好坏,从而影响到下一步搜索扩展结点的方向。通过这种办法可以得到一些差异比较大的主车轨迹,并且轨迹生成时已经随时考虑了与障碍车的交互。
传统的IRL都是人工搞了一大堆的feature,如前后一堆障碍物在轨迹时间维度上的各种feature(如相对s, l和ttc之类的),本文里为了让模型可导,则是直接使用prediction的ego context MLP生成一个Weight数组(size = 1 * C),隐式表征了主车周围的环境信息,然后又用MLP直接接把主车轨迹+对应多模态预测结果转成Feature数组(size = C * N, N指的待选轨迹数),然后两个矩阵相乘得到最终轨迹打分。然后IRL让专家得分最高。个人感觉这里可能是为了计算效率,让decoder尽可能简单,还是有一定的主车信息丢失,如果不关注计算效率,可以用一些更复杂一些的网络连接Ego Context和Predicted Trajectories,应该效果层面会更好?或者如果放弃可导性,这里还是可以考虑再把人工设置的feature加进去,也应该可以提升模型效果。
在耗时方面,该方案采用一次重Encode + 多次轻量化Decode的方法,有效降低了计算时延,文中提到时延可以压到98ms。
在learning based planner中属于SOTA行列,闭环效果接近前一篇文章中提到的nuplan 排第一的Rule Based方案PDM。
看下来,感觉这么个范式是挺不错的思路,中间具体过程可以自己想办法调整:

原文链接:https://mp.weixin.qq.com/s/ZJtMU3zGciot1g5BoCe9Ow
责任编辑:张燕妮 来源: 自动驾驶之心 自动驾驶技术(责任编辑:娱乐)
国家统计局:10月份货物进出口总额33357亿元 出口19408亿元
 11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细]
11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细] 近期,小米成立了MIUI先锋小组,集中解决反馈的各类体验问题,其中就包括手机发热问题。小米产品总监、MIUI体验总负责人金凡表示,手机发热主要有四大原因,包括高规格硬件、充电功率高、5G网络、天气变热
...[详细]
近期,小米成立了MIUI先锋小组,集中解决反馈的各类体验问题,其中就包括手机发热问题。小米产品总监、MIUI体验总负责人金凡表示,手机发热主要有四大原因,包括高规格硬件、充电功率高、5G网络、天气变热
...[详细] 9月6日,备受瞩目的重庆来福士开业,瞬间被刷爆了朋友圈,成为了重庆的新网红地标,甚至一跃登上了微博热搜榜。而落位在来福士一楼核心位置的ONEZONE新北欧设计生活馆,作为首批入驻的品牌店铺,与商场联合
...[详细]
9月6日,备受瞩目的重庆来福士开业,瞬间被刷爆了朋友圈,成为了重庆的新网红地标,甚至一跃登上了微博热搜榜。而落位在来福士一楼核心位置的ONEZONE新北欧设计生活馆,作为首批入驻的品牌店铺,与商场联合
...[详细] 近日,一张说“鸿蒙系统是盗版安卓”的图片在网上传播,而且声称这是中国移动发布的公告。所谓的公告内容显示,“由于华为鸿蒙盗版安卓,得不到WIFI联盟的认证,安装了鸿蒙的设备通过WIFI连接网络会出现网速
...[详细]
近日,一张说“鸿蒙系统是盗版安卓”的图片在网上传播,而且声称这是中国移动发布的公告。所谓的公告内容显示,“由于华为鸿蒙盗版安卓,得不到WIFI联盟的认证,安装了鸿蒙的设备通过WIFI连接网络会出现网速
...[详细]爱美客(300896.SZ)年报推10转8派35元 除权除息日为2021年3月16日
 爱美客(300896.SZ)披露2020年度分红派息、转增股本实施公告,此次实施的利润分配及资本公积金转增股本方案以公司现有的总股本1.202亿股为基数,向全体股东每10股派发35.00元人民币现金(
...[详细]
爱美客(300896.SZ)披露2020年度分红派息、转增股本实施公告,此次实施的利润分配及资本公积金转增股本方案以公司现有的总股本1.202亿股为基数,向全体股东每10股派发35.00元人民币现金(
...[详细] 前不久发布的荣耀50系列,今天正式开卖。价格方面,荣耀50 8+128GB版2699元、8+256GB版2999元,6月16日开启预售,12+256GB版3399元。荣耀50 Pro 8+256GB版
...[详细]
前不久发布的荣耀50系列,今天正式开卖。价格方面,荣耀50 8+128GB版2699元、8+256GB版2999元,6月16日开启预售,12+256GB版3399元。荣耀50 Pro 8+256GB版
...[详细] iPhone 12 mini销量不给力导致停产几乎已经证明了小屏旗舰机是个伪命题,即便是品牌号召力强如苹果也难免遭遇滑铁卢。但这并不代表售价相对便宜一些的小屏产品就没有市场,比如iPhone SE的销
...[详细]
iPhone 12 mini销量不给力导致停产几乎已经证明了小屏旗舰机是个伪命题,即便是品牌号召力强如苹果也难免遭遇滑铁卢。但这并不代表售价相对便宜一些的小屏产品就没有市场,比如iPhone SE的销
...[详细] 《Apex英雄》推出迄今为止已有 4 年时间。开发商重生工作室希望在第 16 赛季中改善新玩家的游戏体验,包括全新的靶场、更好的教程,以及定向匹配机制,帮助新玩家熟悉《Apex》的玩法。但仅仅是游戏玩
...[详细]
《Apex英雄》推出迄今为止已有 4 年时间。开发商重生工作室希望在第 16 赛季中改善新玩家的游戏体验,包括全新的靶场、更好的教程,以及定向匹配机制,帮助新玩家熟悉《Apex》的玩法。但仅仅是游戏玩
...[详细] 银行正在积极开展绿色金融业务,据北京商报记者11月10日不完全统计,今年以来,已有长沙银行、工商银行、南京银行、重庆银行、苏州银行、马鞍山农商行等多家银行获批或已获批发行绿色金融债券。除绿色债券外,在
...[详细]
银行正在积极开展绿色金融业务,据北京商报记者11月10日不完全统计,今年以来,已有长沙银行、工商银行、南京银行、重庆银行、苏州银行、马鞍山农商行等多家银行获批或已获批发行绿色金融债券。除绿色债券外,在
...[详细] 长期以来,电子游戏被认为是一种糟糕的改编素材,但近年来我们已经看到这种变化。由于好莱坞对IP的渴求和游戏发展出更复杂的叙事技巧,游戏实际上已经发展成为电视和电影改编的肥沃土壤。现在,像《质量效应》、《
...[详细]
长期以来,电子游戏被认为是一种糟糕的改编素材,但近年来我们已经看到这种变化。由于好莱坞对IP的渴求和游戏发展出更复杂的叙事技巧,游戏实际上已经发展成为电视和电影改编的肥沃土壤。现在,像《质量效应》、《
...[详细] 波音公司是哪个国家的 波音公司创始人是威廉爱德华波音吗?
波音公司是哪个国家的 波音公司创始人是威廉爱德华波音吗? 国外网友展示DIY苹果手机 强加USB
国外网友展示DIY苹果手机 强加USB 《超级马里奥大电影》30秒广告 兄弟管道生意兴隆
《超级马里奥大电影》30秒广告 兄弟管道生意兴隆 迪士尼“大小孩俱乐部”主题活动登陆广州天河城
迪士尼“大小孩俱乐部”主题活动登陆广州天河城 换手率是什么意思 股票跌停板换手率高是什么原因?
换手率是什么意思 股票跌停板换手率高是什么原因?