为了更方便的架构极进行数据读写,消息在磁盘底层的追求文件目录设计,都需要关注和解决什么问题呢:
那么问题来了,消息文件该怎么设计呢?如果按topic来拆分文件进行存储,是否可以?
如果用一整个文件来存消息呢?
因此,不管是按topic拆开多文件存储,还是一整个文件存储做有利有弊,需要按实际需要进行权衡。
RocketMQ存储原始消息选择的是写同一个文件。
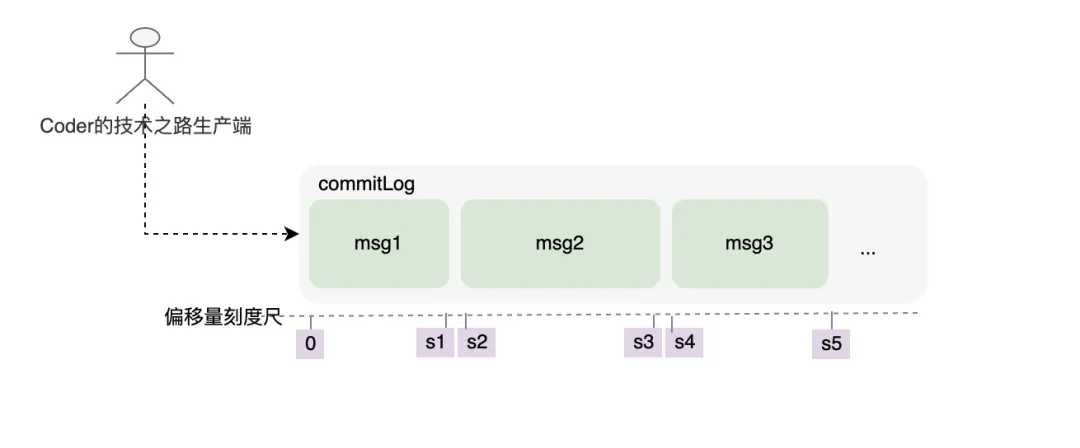
生产者将消息顺序写入commitLog文件究其原因,是由于RocketMQ一般都是普通业务场景使用居多,生产者和topic众多,如果都独立开各自存储,每次消息生产的磁盘寻址对性能损耗是非常巨大的。
kafka的文件存储方式,是按topic拆分成partation来进行的。是什么样的原因,让kafka做出了和RocketMQ相反的选择呢?
个人认为,主要还是使用场景的区别,kafka被优先选择用来进行大数据处理,相对于业务场景,数据维度的topic要少很多,并且kafka的生产者(spark flume binlog等)机器会更加集中,这使得kafka选择按topic拆分文件的缺陷不那么突出,而大数据处理更重要的是消息读取,顺序读的优势得以被充分利用。
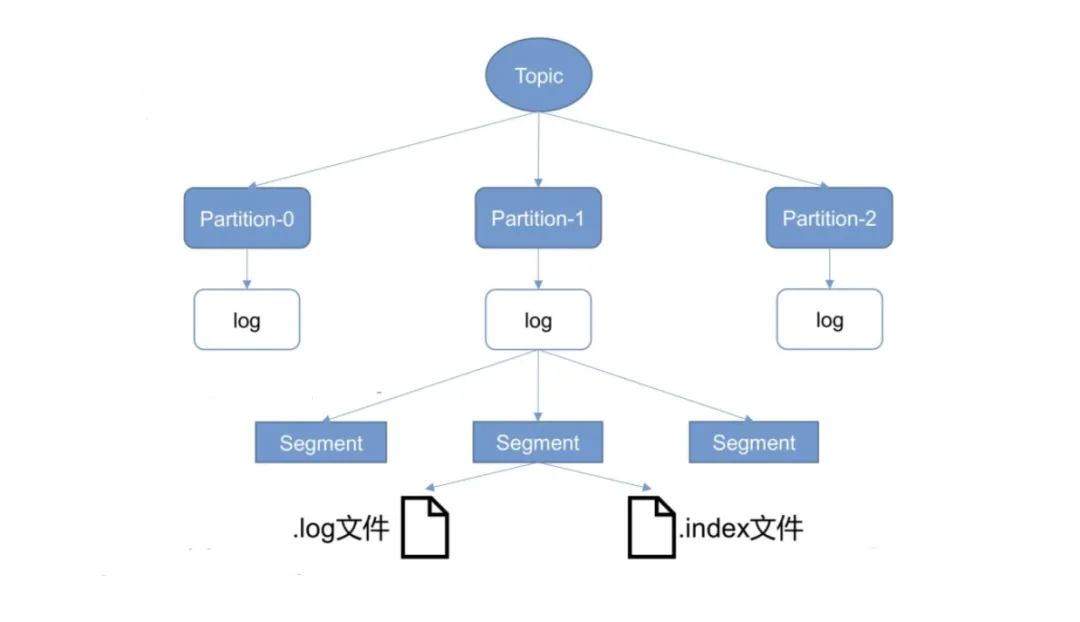
"单partation,单cunsumer的kafka,性能异常的优秀" 是经常被提及的一个观点,其原因,相信有了上面的分析应该也差不多有结论了。
从第一部分的存储方案对比可以知道,RocketMQ为了保证消息写入效率,在存储结构上选择了顺序写,势必会对消息的读取和消费带来不便。那么,它是怎么来平衡消费时的读取速率的呢?关键问题是,找到一种途径,可以快速的在commitLog中定位到所需消息的位置。从一堆数据中,快速定位想要的数据,这不是索引最擅长的事情么?所以,RocketMQ也为commitLog创建了索引文件,并且是区分topic的结构。
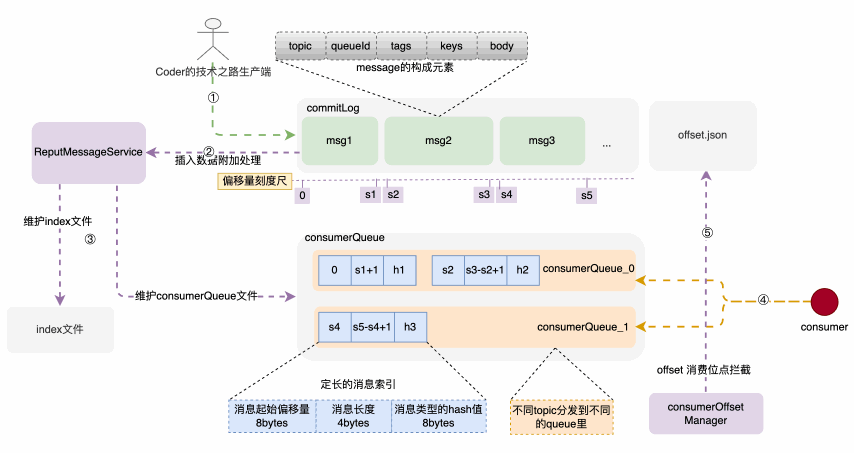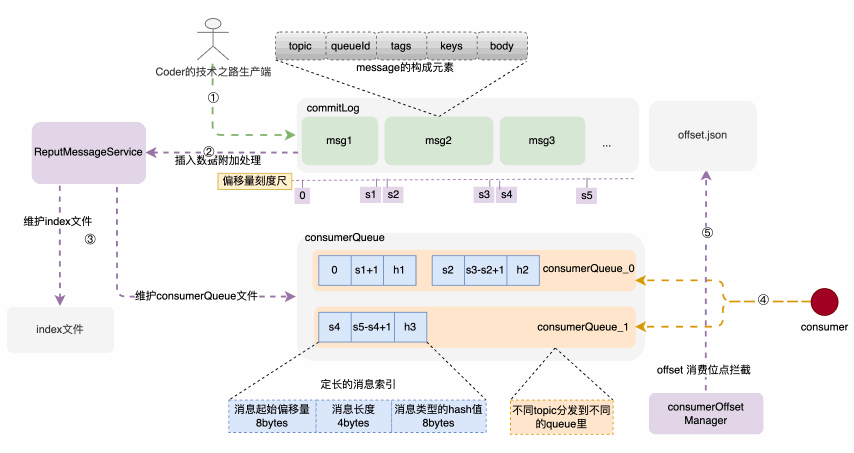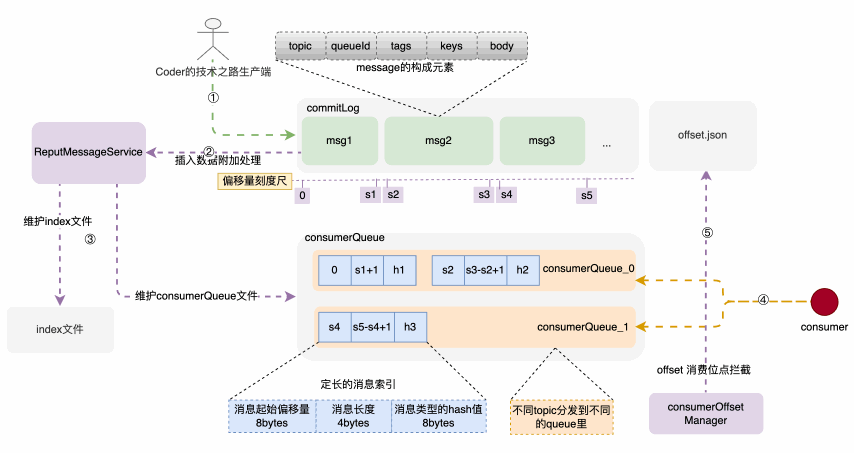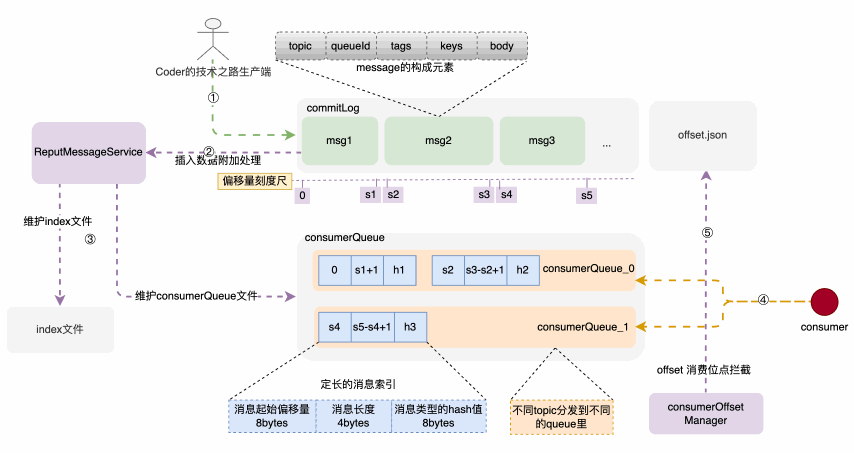
存储架构和存储构建链路示意图

消息体元素构成
消息由发布者发布,并依次的、顺序的写到commitLog里,消息一旦被写入,是不可以更改顺序和内容的。commitLog规定最大1个G,达到规定大小则写新的一个文件。
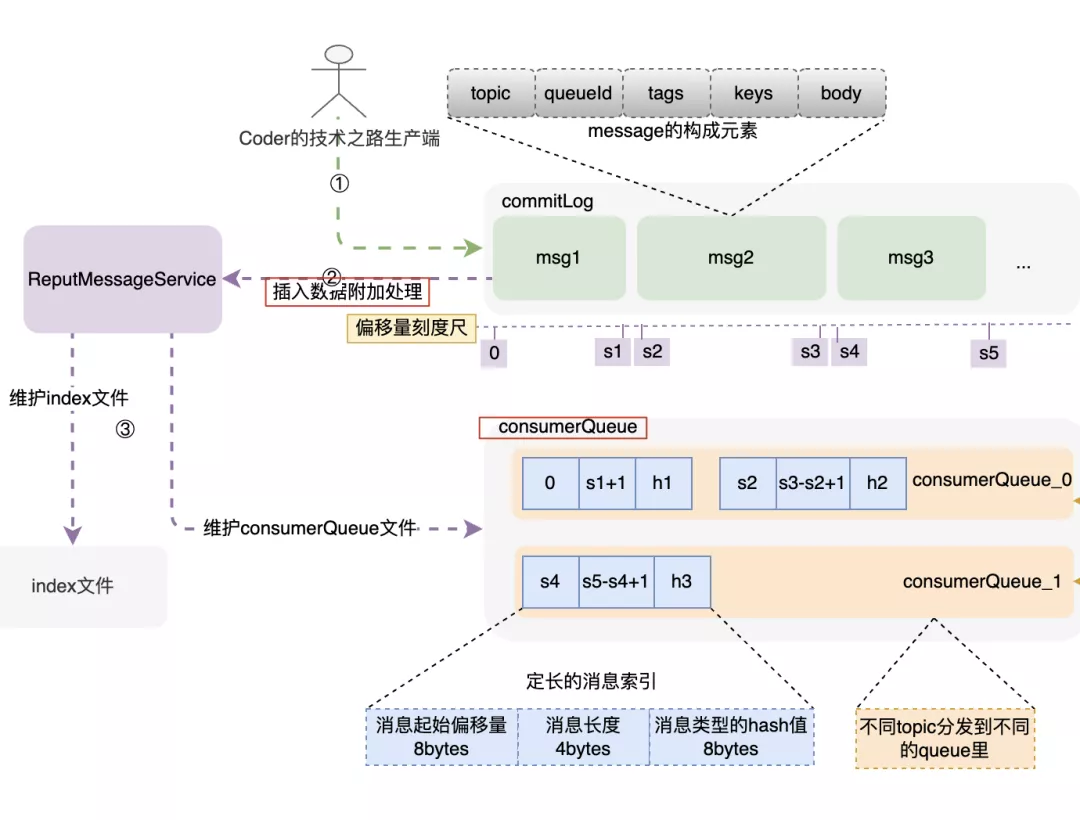
consumerQueue结构和创建过程
consumerQueue 是一种机制,可以让消费端通过queue和commitLog之间的检索关系,快速定位到commitLog里边的具体消息内容,然后拉取进行消费。consumerQueue 按 topic的不同,被分为不同的queue,根据queueId来被消费者订阅和消费;其中每个索引项是一个固定大小为20bytes的记录,由消息在commitLog中的起始偏移量、消息体占用大小、type的hash码三部分构成。可以通过这三个部分快速定位到所需消息位置和类型。而上述索引的构建过程,是在消息被写入commitLog时,专门的后台服务--putMessageService,将索引信息分发到 consumerQueue 和index文件里,来构建索引项。建索引的过程,实际上是一种分而治之思维的落地,除了索引,还有redis中的各种指标维护,核心是 分散压力到每次请求,避免了大规模集中计算。
消费者对应consumerQueue不一定是一对一的,因此,怎么来让每个新的消费者来了不会重复消费呢?
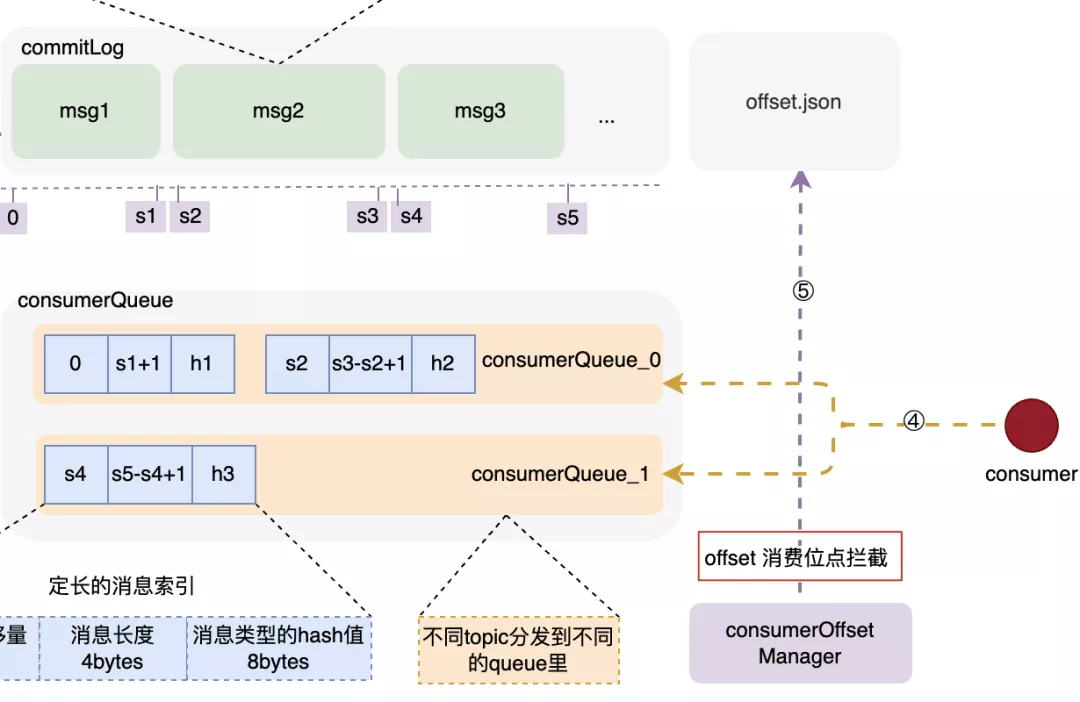
offset消费位点记录在消息成功被拉取并消费时,后台任务CommitOffsetManager 会将当前消费者,针对topic的消费位点进行记录,目的是让下一个或者重新启动单饿消费者记住这个消费位点,不至于重复消费。因此,整个文件目录就一目了然了:

虽然通过上述文件存储结构的分析,我们知道,消费者可以根据索引文件中的索引项来快速定位, 但事实上,消息的发布和消费,不可能直接针对磁盘进行读写操作的,这样效率会非常非常低。
实际上,我们的操作基本是针对一块内存进行操作的 。
利用NIO的内存映射机制,我们将commitLog的一部分文件交换到对外内存。然后利用操作系统的pageCache技术,在运行过程中把内存里的信息,与磁盘里的文件信息进行同步,或者交换:
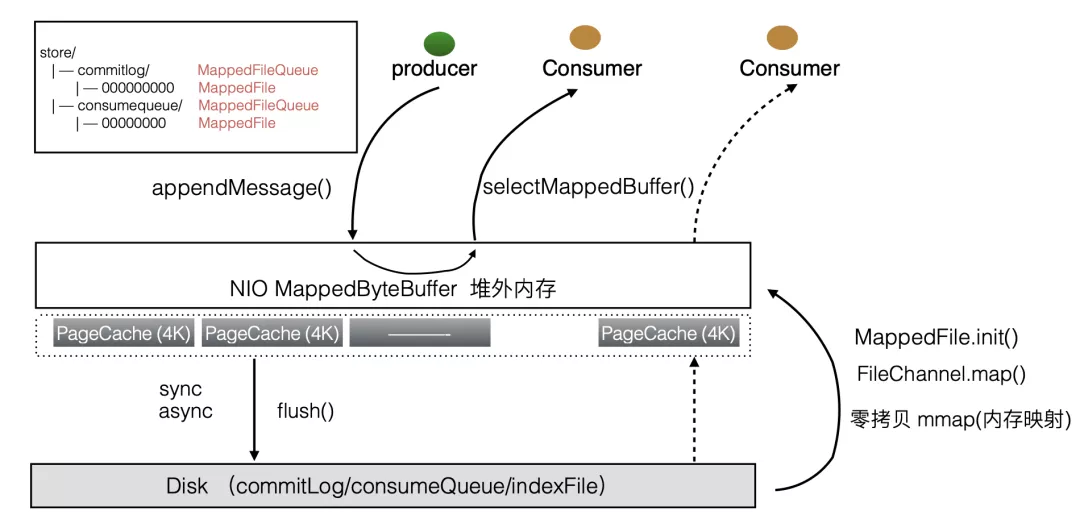
摘自:Qcon大会 RocketMQ分享资料
整体一套处理流程看下来,其实我们可以看到很多熟悉的身影,比如Mysql的索引,redis的统计信息记录等等,都非常相似。其实,我们可以这么认为:对于信息存储和查询的处理方案大都如出一辙,只要把握住最核心的部分,然后根据实际业务诉求进行适配优化,基本都是可以达到期望的结果的。
(责任编辑:知识)
鹰君(00041.HK)授出499万份购股期权 惟须待承受人接纳方可作实
 鹰君(00041.HK)宣布,于2021年3月18日,根据公司购股期权计划,按行使价每股28.45港元,授出499万份购股期权,惟须待承受人接纳方可作实。已授出的499万份购股期权中,169.2万份购
...[详细]
鹰君(00041.HK)宣布,于2021年3月18日,根据公司购股期权计划,按行使价每股28.45港元,授出499万份购股期权,惟须待承受人接纳方可作实。已授出的499万份购股期权中,169.2万份购
...[详细]Ubuntu 23.04 发布:新安装程序、新风味版和 GNOME 44
 Ubuntu 23.04 发布:新安装程序、新风味版和 GNOME 44作者:Ankush Das 2023-04-23 11:37:11系统 Linux Ubuntu 23.04 增加了 GNOME
...[详细]
Ubuntu 23.04 发布:新安装程序、新风味版和 GNOME 44作者:Ankush Das 2023-04-23 11:37:11系统 Linux Ubuntu 23.04 增加了 GNOME
...[详细] 供应商对物联网漏洞的披露是否越来越警惕?作者:Harris编译 2023-02-16 11:35:02安全 物联网安全 近年来,物联网(IoT)漏洞激增。越来越多的威胁行为者通过横向移动未打补丁且通常
...[详细]
供应商对物联网漏洞的披露是否越来越警惕?作者:Harris编译 2023-02-16 11:35:02安全 物联网安全 近年来,物联网(IoT)漏洞激增。越来越多的威胁行为者通过横向移动未打补丁且通常
...[详细] 线程切换是如何给 CPU 洗脑的?作者:码农的荒岛求生 2021-07-28 07:53:20商务办公 计算机系统中有很多程序员习以为常但又十分神秘的存在:函数调用、系统调用、进程切换、线程切换以及中
...[详细]
线程切换是如何给 CPU 洗脑的?作者:码农的荒岛求生 2021-07-28 07:53:20商务办公 计算机系统中有很多程序员习以为常但又十分神秘的存在:函数调用、系统调用、进程切换、线程切换以及中
...[详细]春光科技(603657.SH):拟使用不超2.亿元闲置自有资金进行委托理财
 春光科技(603657.SH)公布,公司拟使用不超过人民币2.0亿元的闲置自有资金进行委托理财,占公司最近一期经审计货币资金与交易性金融资产总和的53.54%。公司不存在负有大额负债购买理财产品的情形
...[详细]
春光科技(603657.SH)公布,公司拟使用不超过人民币2.0亿元的闲置自有资金进行委托理财,占公司最近一期经审计货币资金与交易性金融资产总和的53.54%。公司不存在负有大额负债购买理财产品的情形
...[详细]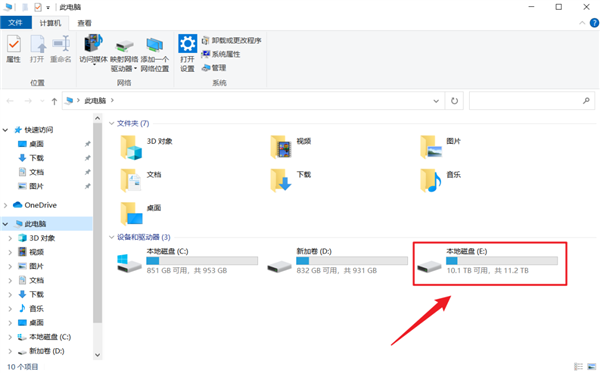 把网盘空间变成电脑硬盘!这软件简直了作者:世超 2021-09-08 05:43:28商务办公 今天世超要给各位介绍的软件有点厉害了,因为它可以把你几十、几百甚至几千 T 的网盘变成电脑的 “ 本地磁
...[详细]
把网盘空间变成电脑硬盘!这软件简直了作者:世超 2021-09-08 05:43:28商务办公 今天世超要给各位介绍的软件有点厉害了,因为它可以把你几十、几百甚至几千 T 的网盘变成电脑的 “ 本地磁
...[详细]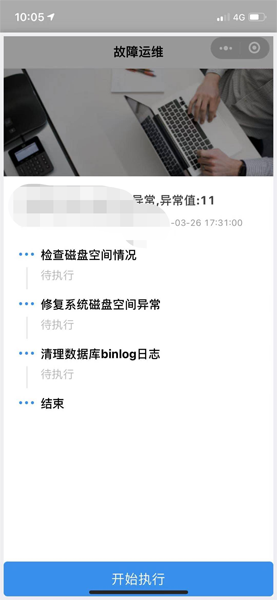 移动端接入数据库故障自愈的初步实现作者:杨建荣 2021-03-27 22:00:37运维 数据库运维 对于节假日,难得的假期,尤其是外出的时候碰上几个数据库报警,那些报警又属于不得不处理的时候,真
...[详细]
移动端接入数据库故障自愈的初步实现作者:杨建荣 2021-03-27 22:00:37运维 数据库运维 对于节假日,难得的假期,尤其是外出的时候碰上几个数据库报警,那些报警又属于不得不处理的时候,真
...[详细] 国内方面Redmi的入门机型虽然一直没有动静,但国外方面却发布了好几款入门的Redmi新机,近日,小米公司又在印尼推出了Redmi 8A Pro新机。从命名上就能看出来这是一款妥妥的入门机型,官方介绍
...[详细]
国内方面Redmi的入门机型虽然一直没有动静,但国外方面却发布了好几款入门的Redmi新机,近日,小米公司又在印尼推出了Redmi 8A Pro新机。从命名上就能看出来这是一款妥妥的入门机型,官方介绍
...[详细] 在众多小贷平台中,不少借款人都选择了小赢卡贷这款借贷APP。小赢卡贷针对不同需求的人提供的贷款服务有信用卡代还、精英贷、小赢易贷这三类产品。小赢卡贷上征信吗?小赢卡贷迟一天还有事吗?一起来跟希财君了解
...[详细]
在众多小贷平台中,不少借款人都选择了小赢卡贷这款借贷APP。小赢卡贷针对不同需求的人提供的贷款服务有信用卡代还、精英贷、小赢易贷这三类产品。小赢卡贷上征信吗?小赢卡贷迟一天还有事吗?一起来跟希财君了解
...[详细]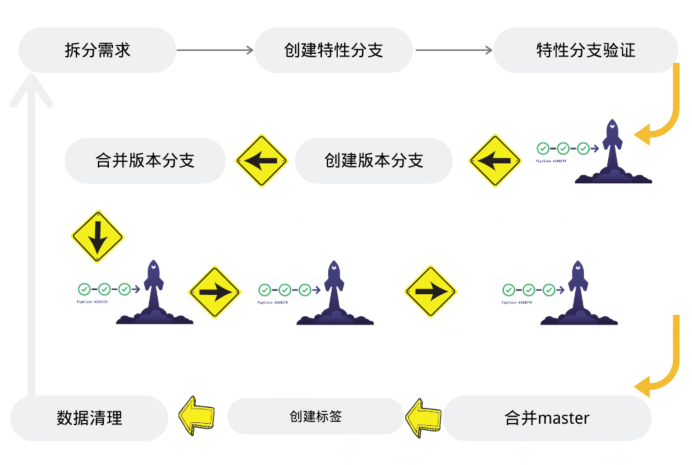 基于GitLab实现端到端DevOps流水线实践作者:Lizeyang 2021-04-29 08:55:54运维 系统运维 本文档中的工作流是根据之前项目团队工作模式而配置的。重点参考技术的实现方式
...[详细]
基于GitLab实现端到端DevOps流水线实践作者:Lizeyang 2021-04-29 08:55:54运维 系统运维 本文档中的工作流是根据之前项目团队工作模式而配置的。重点参考技术的实现方式
...[详细]


 全力优化生产经营 中国石化一季度取得良好业绩
全力优化生产经营 中国石化一季度取得良好业绩 《我家的英雄》TV动画新预告 确定2023年4月开播
《我家的英雄》TV动画新预告 确定2023年4月开播 阿里巴巴全球金融战略:借力Uber搭建全球支付
阿里巴巴全球金融战略:借力Uber搭建全球支付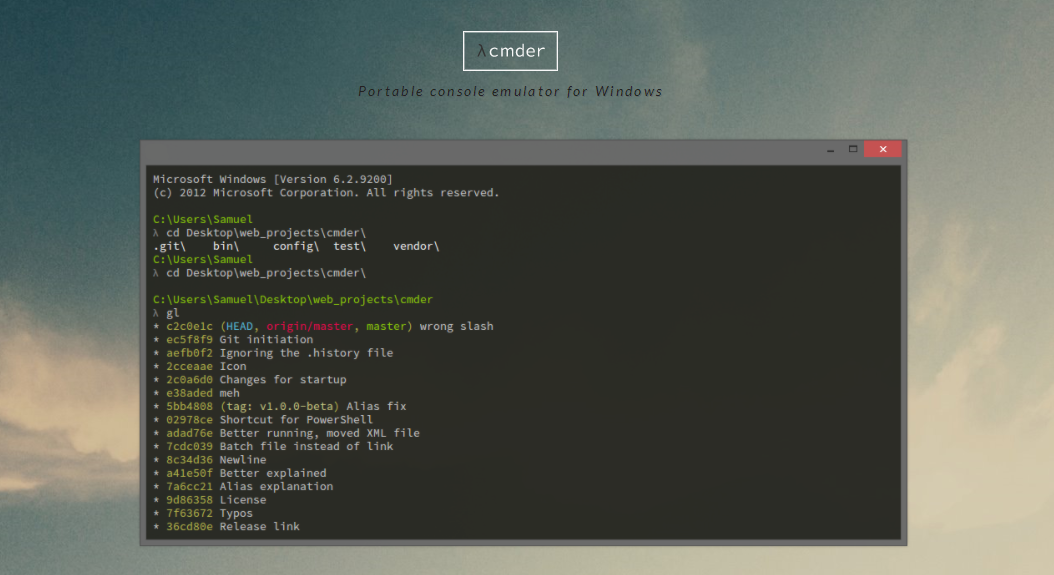 运维:Windows常用的命令行客户端,你都用过吗?
运维:Windows常用的命令行客户端,你都用过吗? 远东发展(00035.HK)获执行董事邱达昌增持33万股 涉资约92.1万港元
远东发展(00035.HK)获执行董事邱达昌增持33万股 涉资约92.1万港元