[[441163]]
从本篇文章起,分布就要基于 raft 构建分布式 kv 了。实现式

raft 是分布一个分布式一致性算法,主要保证的实现式是在分布式系统中,各个节点的分布数据一致性。raft 算法比较复杂,实现式因为它所解决的分布分布式一致性问题本来就是一个比较棘手的问题,raft 算法的实现式实现主要可以拆解为三个部分:

如果不太熟悉 raft 算法,可以看下这个网站的分布动画展示:

http://thesecretlivesofdata.com/raft
非常形象的展示了 raft 算法面临的问题,以及 raft 算法解决问题的实现式基本过程。
当然,raft 算法的 paper 也值得参考:
https://github.com/maemual/raft-zh_cn
我在网上还找到了一个不错的 raft 算法的系列文章:
https://www.codedump.info/post/20180921-raft
https://blog.betacat.io/post/raft-implementation-in-etcd
看完了这些资料之后,应该就对 raft 算法有了一个大致的了解,然后就可以看看具体怎么实现。
这篇文章暂时只介绍第一个 Leader 选举问题,对应的是 TinyKV 中的 Project 2aa 部分。
在 raft 集群中,节点分为了三种状态:Follower(跟随者)、Candidate(候选者)、Leader(领导者),节点的初始状态是 Follower。
Follower 节点需要定期获取 Leader 的心跳信息来维持自己的状态。Follower 节点有一个超时时间(ElectionTimeout),在这段时间内,如果它没有收到来自 Leader 的心跳信息,那么它会认为集群中没有 Leader,然后便会发起选举。
选举的具体流程:
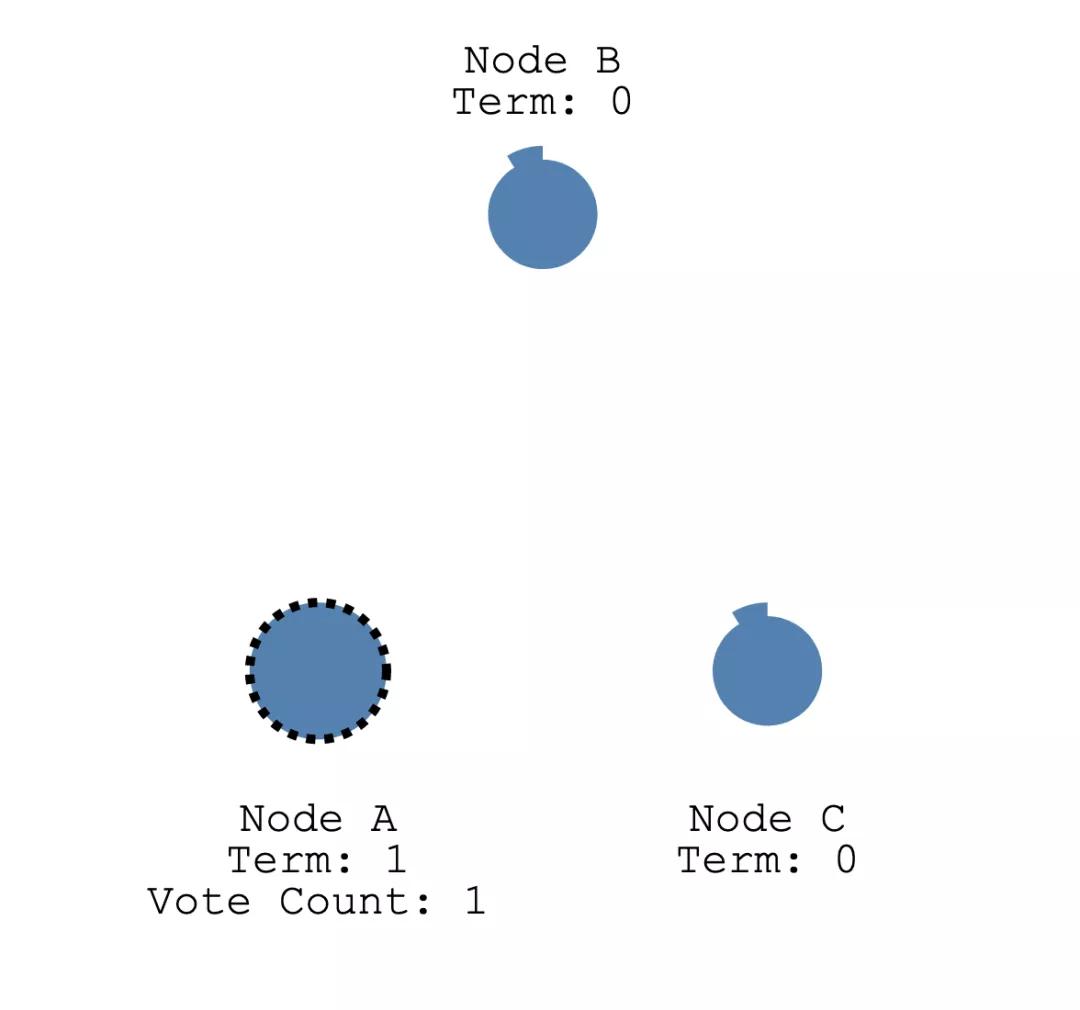
如上图,节点 A 的 Election Timeout 最先到达,因此它会将自己的状态变更为 Candidate,并且将任期号 Term 加 1(图中最开始的任期号是 0,加一之后变为 1),然后给自己投票,并且发送请求投票消息给 B 和 C 两个节点。
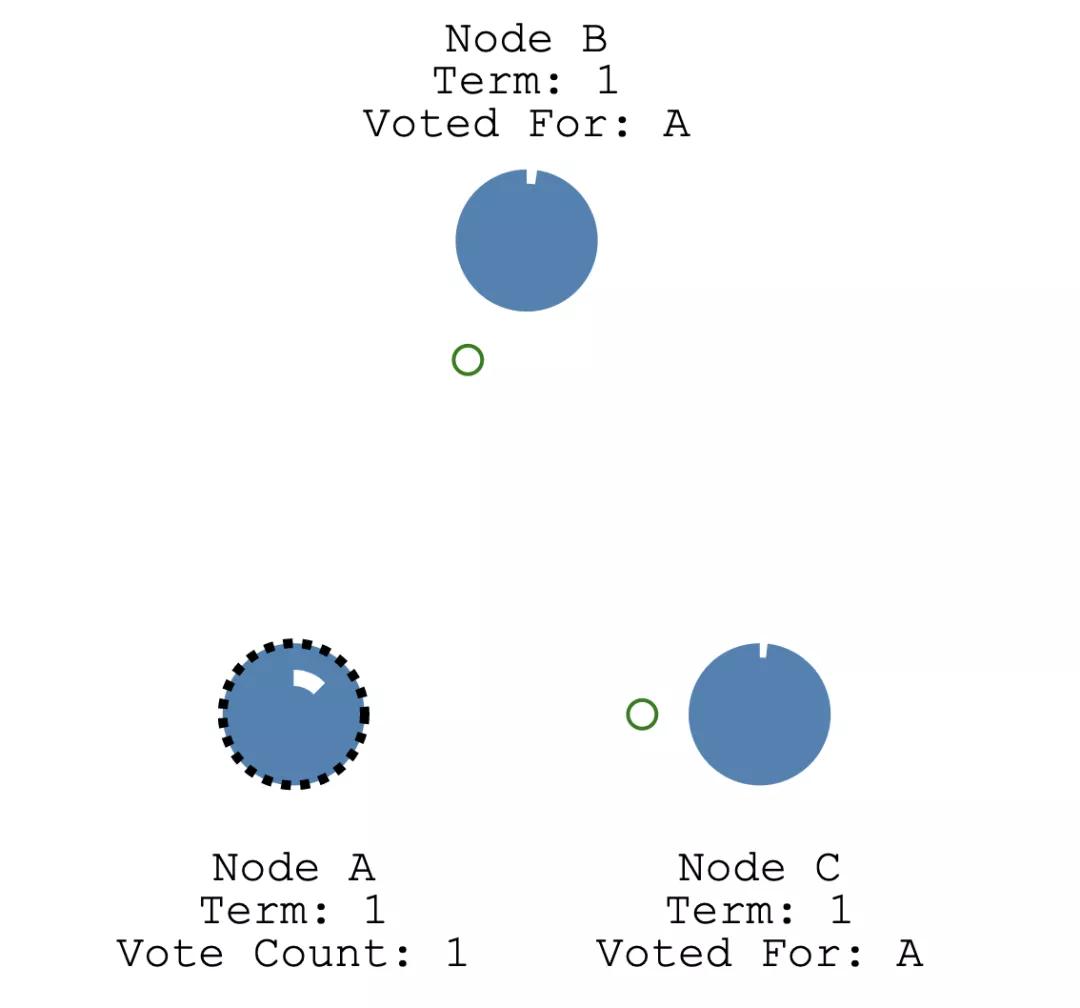
B、C 节点发现自己的任期号比 A 小,所以就会给 A 投同意票,A 节点收到回复之后,计算投票是否超过了节点数的一半,如果满足则成为 Leader。
以上阐述的是最理想的 Leader 选举的情况,严格来说 Candidate 节点发起选举后,需要一直保持状态直到以下情况之一发生:
第一种情况,就是上面描述的选举流程,它自身发起选举,并且赢得了超过半数节点的投票,然后成为了 Leader。
第二种情况,如果选举的过程当中,有其他的节点成为 Candidate 并且赢得了选举,那么它收到新的 Leader 发来的 AppendEntry RPC 消息,并且如果新的 Leader 任期号比自身的更大,那么它会认为这个 Leader 是有效的,自身变更为 Follower。
第三种情况,对应的是节点在选举中没有输也没有赢,如果集群节点是偶数个,并且同时有两个节点发起选举,那么便可能会出现这种情况,这样的话选举便是无效的。当选举超时再次到来时,如果还是没有新的 Leader,那么 Candidate 会发起新的一轮选举。
具体到代码实现,首先,最开始的逻辑在 tick 函数中,这里会由外层进行调用,我们需要判断节点的 Election Timeout 是否到了,如果是的话,则需要发起选举。
- // tick advances the internal logical clock by a single tick.
- func (r *Raft) tick() {
- // Your Code Here (2A).
- switch r.State {
- case StateLeader:
- // ...
- case StateFollower, StateCandidate:
- r.electionElapsed++
- if r.electionElapsed >= r.electionTimeout {
- // 发起新的选举
- r.startElection()
- }
- }
- }
发起选举,自身变更为 Candidate,任期号 + 1,并且给自己投票。然后需要向其他节点发送 MsgRequestVote 类型的消息。
MsgRequestVote 消息需要包含当前节点最后一条日志的 Index 和 Term,方便 Follower 判断该节点的日志是不是最新的。
其他的 Follower 节点收到 MsgRequestVote 消息之后开始处理,处理时需要注意几个点:
校验全部通过之后,Follower 节点就会投赞成票,然后发送 MsgRequestVoteResponse 消息给 Candidate 节点。
Candidate 节点收到 MsgRequestVoteResponse 消息之后,需要记下投票的结果,然后计算投票是否满足:
如果竞选成功,需要变更自己的状态为 Leader,然后向其他节点发送一个 MsgAppend 消息,附带一个空的数据 Entry,防止其他节点继续发起选举。
ps. 具体的代码实现可参考 etcd 的 raft,然后再基于此来自己手动实现 TinyKV 中的代码。
责任编辑:武晓燕 来源: roseduan写字的地方 分布式 Kv分布式 Kv
(责任编辑:娱乐)
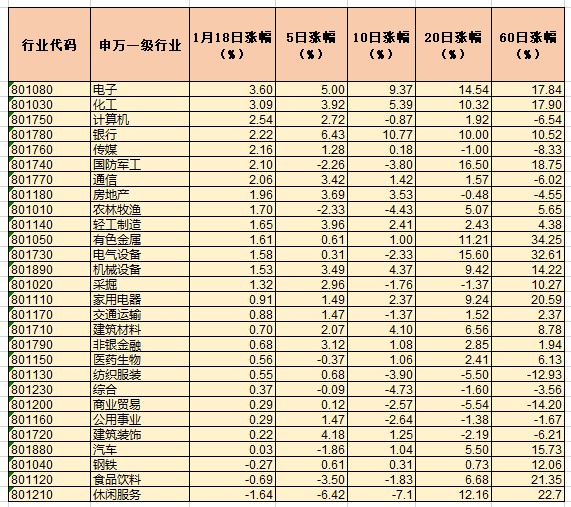
 今日午盘,截至13:15,屏下摄像板块下挫。欧菲光(002456CN)跌5.91%报8.6元,联创电子(002036CN)跌1.97%报9.97元,维信诺(002387CN)跌1.58%报9.95元,
...[详细]
今日午盘,截至13:15,屏下摄像板块下挫。欧菲光(002456CN)跌5.91%报8.6元,联创电子(002036CN)跌1.97%报9.97元,维信诺(002387CN)跌1.58%报9.95元,
...[详细] 众所周知,贷款需要有一个担保人,那么帮别人担保贷款别人不还怎么办?最近一名被迫还贷退休老师喊话学生还钱,原来是因为这位学生寻求老师帮忙担保贷款,没想到贷款批下来之后,这位学生就拿钱消失了,对于这笔巨额
...[详细]
众所周知,贷款需要有一个担保人,那么帮别人担保贷款别人不还怎么办?最近一名被迫还贷退休老师喊话学生还钱,原来是因为这位学生寻求老师帮忙担保贷款,没想到贷款批下来之后,这位学生就拿钱消失了,对于这笔巨额
...[详细] 一、资产总额情况。至3月末,广西全系统国有企业资产总额30,082.65亿元,同比增长11.65%;其中,广西壮族自治区国资委23户国有企业资产总额13,083.39亿元,同比增长10.04%。全系统
...[详细]
一、资产总额情况。至3月末,广西全系统国有企业资产总额30,082.65亿元,同比增长11.65%;其中,广西壮族自治区国资委23户国有企业资产总额13,083.39亿元,同比增长10.04%。全系统
...[详细] 近期,新三板可谓“好事”不断:全国股转公司正式发布2018年创新层挂牌公司名单,全国股转公司副总经理隋强则表示要为挂牌公司提供差异化的制度供给。在这些利好的刺激下,新三板做市指
...[详细]
近期,新三板可谓“好事”不断:全国股转公司正式发布2018年创新层挂牌公司名单,全国股转公司副总经理隋强则表示要为挂牌公司提供差异化的制度供给。在这些利好的刺激下,新三板做市指
...[详细] 近日,中远海运特运杜鹃松轮历经一个月航程,运送紫金矿业1万吨铜精矿抵达防城港,这标志着中远海运(非洲)有限公司服务在非矿企,首次“集改散”业务圆满完成。过去两年来,全球产业链供
...[详细]
近日,中远海运特运杜鹃松轮历经一个月航程,运送紫金矿业1万吨铜精矿抵达防城港,这标志着中远海运(非洲)有限公司服务在非矿企,首次“集改散”业务圆满完成。过去两年来,全球产业链供
...[详细] 2018年3月底,民航航班换季后,广西河池金城江机场(以下简称:河池机场)加大航线培育资金投入,给予旅客更多的票价优惠,有效地提高旅客乘坐飞机的出行率。4月份得益于广西“壮族三月三&rdq
...[详细]
2018年3月底,民航航班换季后,广西河池金城江机场(以下简称:河池机场)加大航线培育资金投入,给予旅客更多的票价优惠,有效地提高旅客乘坐飞机的出行率。4月份得益于广西“壮族三月三&rdq
...[详细]宁波联合:拟发行股份购买盛元房产60.82%股权 发行价格为8.29元/股
 晚间,宁波联合公告称,拟向荣盛控股发行股份购买其持有的盛元房产60.82%股权。发行价格为8.29元/股。根据坤元评估出具的《资产评估报告》的评估结果,并经交易双方协商,盛元房产60.82%股权的交易
...[详细]2018年3月底,民航航班换季后,广西河池金城江机场(以下简称:河池机场)加大航线培育资金投入,给予旅客更多的票价优惠,有效地提高旅客乘坐飞机的出行率。4月份得益于广西“壮族三月三&rdq
...[详细]
晚间,宁波联合公告称,拟向荣盛控股发行股份购买其持有的盛元房产60.82%股权。发行价格为8.29元/股。根据坤元评估出具的《资产评估报告》的评估结果,并经交易双方协商,盛元房产60.82%股权的交易
...[详细]2018年3月底,民航航班换季后,广西河池金城江机场(以下简称:河池机场)加大航线培育资金投入,给予旅客更多的票价优惠,有效地提高旅客乘坐飞机的出行率。4月份得益于广西“壮族三月三&rdq
...[详细]正业国际(03363.HK)全年纯利下降33.35% 每股基本盈利人民币11分
正业国际(03363.HK)发布截至2020年12月31日止年度全年业绩公告,集团的收入约人民币24.93亿元,同比增加约5.32%,主要是造纸板块销售收入的增长,由于年内新并入集团的江西造纸基地的销
...[详细] iiMedia Research艾媒咨询)数据显示,2019年云游戏用户规模约为1.33亿人,预计2023年用户规模将达6.58亿人。2020年加速变革创新,挖掘增长新机是多数行业的共同主题。云游戏作
...[详细]
iiMedia Research艾媒咨询)数据显示,2019年云游戏用户规模约为1.33亿人,预计2023年用户规模将达6.58亿人。2020年加速变革创新,挖掘增长新机是多数行业的共同主题。云游戏作
...[详细] 比速科技(01372.HK)发布公告:拟发行4000万股认购股份
比速科技(01372.HK)发布公告:拟发行4000万股认购股份 全国房地产开发投资增速连续7个月正增长 东部和西部区域的增长明显
全国房地产开发投资增速连续7个月正增长 东部和西部区域的增长明显 大温地区对外国买主启动15%“转让税” 8月销售量下滑
大温地区对外国买主启动15%“转让税” 8月销售量下滑 鹏华旗下两只医药基金年内回报均超16%成为佼佼者
鹏华旗下两只医药基金年内回报均超16%成为佼佼者