Meta 公司发布了一个新的型整开源人工智能模型 ImageBind,该模型能够将多种数据流,合文包括文本、本音音频、视觉数据、温度和运动读数等整合在一起。该模型目前只是一个研究项目,还没有直接的消费者或实际应用,但它展示了未来生成式人工智能系统的可能性,这些系统能够创造出沉浸式、多感官的体验。同时,该模型也表明了 Meta 公司在人工智能研究领域的开放态度,而其竞争对手如 OpenAI 和谷歌则变得越来越封闭。
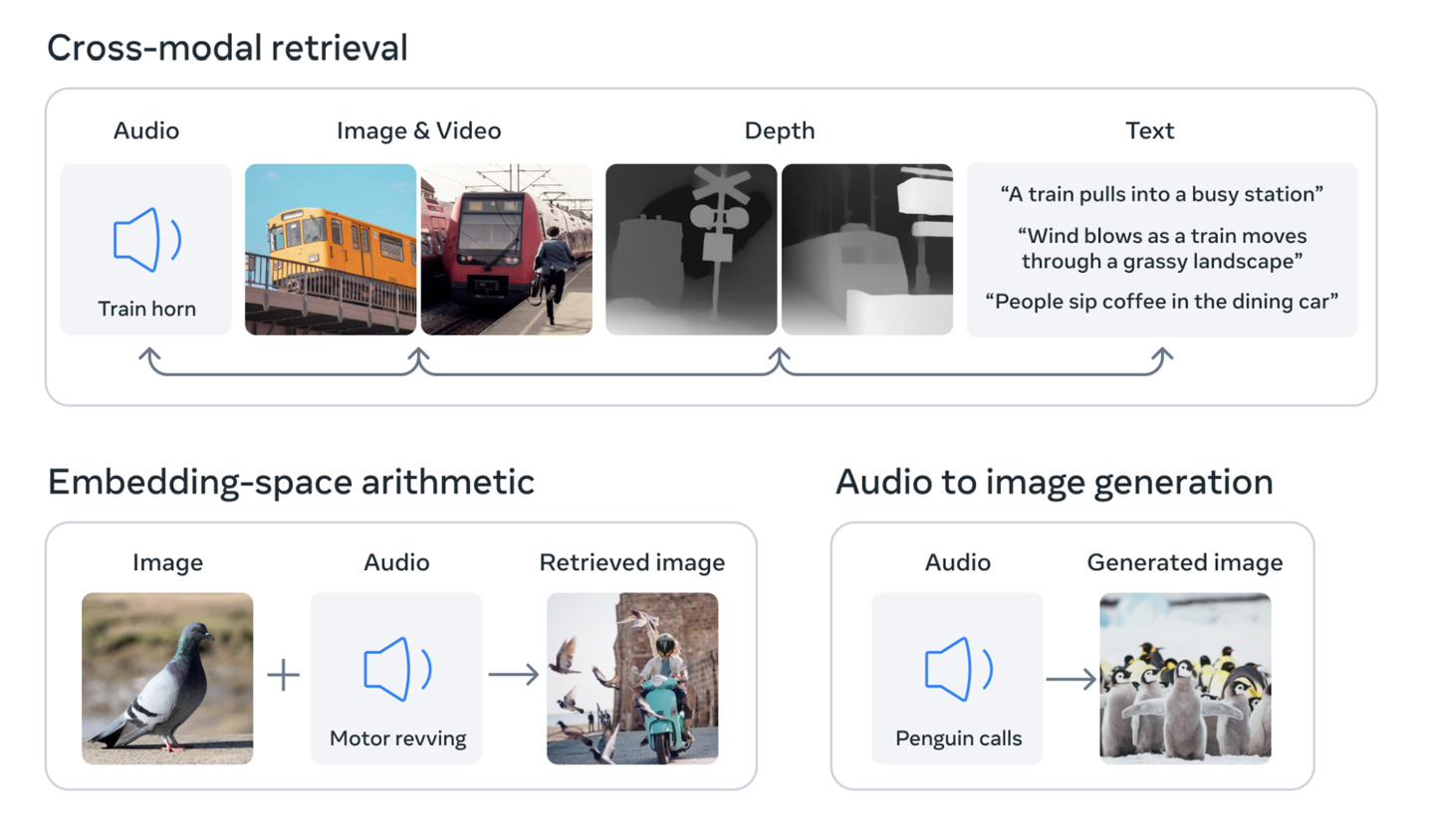

该研究的核心概念是将多种类型的数据整合到一个多维索引(或用人工智能术语来说,“嵌入空间”)中。这个概念可能有些抽象,但它正是近期生成式人工智能热潮的基础。例如,人工智能图像生成器,如 DALL-E、Stable Diffusion 和 Midjourney 等,都依赖于在训练阶段将文本和图像联系在一起的系统。它们在寻找视觉数据中的模式的同时,将这些信息与图像的描述相连。这就是为什么这些系统能够根据用户的文本输入生成图片。同样的道理也适用于许多能够以同样方式生成视频或音频的人工智能工具。

Meta 公司称,其模型 ImageBind 是第一个将六种类型的数据整合到一个嵌入空间中的模型。这六种类型的数据包括:视觉(包括图像和视频);热力(红外图像);文本;音频;深度信息;以及最有趣的一种 —— 由惯性测量单元(IMU)产生的运动读数。(IMU 存在于手机和智能手表中,用于执行各种任务,从手机从横屏切换到竖屏,到区分不同类型的运动。)

未来的人工智能系统将能够像当前针对文本输入的系统一样,交叉引用这些数据。例如,想象一下一个未来的虚拟现实设备,它不仅能够生成音频和视觉输入,还能够生成你所处的环境和物理站台的运动。你可以要求它模拟一次漫长的海上旅行,它不仅会让你置身于一艘船上,并且有海浪的声音作为背景,还会让你感受到甲板在脚下摇晃和海风吹拂。
Meta 公司在博客文章中指出,未来的模型还可以添加其他感官输入流,包括“触觉、语音、气味和大脑功能磁共振成像信号”。该公司还声称,这项研究“让机器更接近于人类同时、全面、直接地从多种不同的信息形式中学习的能力。”
当然,这很多都是基于预测的,而且很可能这项研究的直接应用会非常有限。例如,去年,Meta 公司展示了一个人工智能模型,能够根据文本描述生成短而模糊的视频。像 ImageBind 这样的研究显示了未来版本的系统如何能够整合其他数据流,例如生成与视频输出匹配的音频。
对于行业观察者来说,这项研究也很有趣,因为IT之家注意到 Meta 公司是开源了底层模型的,这在人工智能领域是一个越来越受到关注的做法。
责任编辑:姜华 来源: IT之家 开源人工智能(责任编辑:探索)
中国海油牵头签订国内最大规模液化天然气船舶建造项目 建造金额约160亿元
 4月28日,中国海油以“云签约”方式牵头签订6艘液化天然气(LNG)运输船建造项目合同(下称船运项目)。加上今年1月初签订的6艘建造合同,该项目将开工建造12艘LNG运输船,建
...[详细]
4月28日,中国海油以“云签约”方式牵头签订6艘液化天然气(LNG)运输船建造项目合同(下称船运项目)。加上今年1月初签订的6艘建造合同,该项目将开工建造12艘LNG运输船,建
...[详细] 本周新奇酷应用见面了,国庆长假过得怎样,有没有假日综合症呢,如果有的话,可以看看这篇文章收收心了哈哈,练字就是练心这句很酷的话听过没有?写字先生 Android iPhone平常写字写的好吗?谁不想在
...[详细]
本周新奇酷应用见面了,国庆长假过得怎样,有没有假日综合症呢,如果有的话,可以看看这篇文章收收心了哈哈,练字就是练心这句很酷的话听过没有?写字先生 Android iPhone平常写字写的好吗?谁不想在
...[详细]Redmi K70配置曝光:搭载骁龙8 Gen3+120W快充
 知名数码博主“数码闲聊站”爆料称,Redmi K70全系标配无塑料支架并搭载极窄2K直屏。性能方面,Redmi K70系列将搭载骁龙8 Gen3移动平台,内置5120mAh大容量电池,支持120W有线
...[详细]
知名数码博主“数码闲聊站”爆料称,Redmi K70全系标配无塑料支架并搭载极窄2K直屏。性能方面,Redmi K70系列将搭载骁龙8 Gen3移动平台,内置5120mAh大容量电池,支持120W有线
...[详细] 知名数码博主“数码闲聊站”爆料称,小米新款折叠屏将于下月登场,主打“轻薄旗舰”。评论区有人问小米MIX Fold 3的影像配置,“数码闲聊站”给到了回复。由此来看,下个月,小米似乎会更新小米MIX F
...[详细]
知名数码博主“数码闲聊站”爆料称,小米新款折叠屏将于下月登场,主打“轻薄旗舰”。评论区有人问小米MIX Fold 3的影像配置,“数码闲聊站”给到了回复。由此来看,下个月,小米似乎会更新小米MIX F
...[详细]东阿阿胶(000423.SZ)2020年度业绩扭亏为盈至4328.93万元 基本每股收益0.07元
 东阿阿胶(000423.SZ)发布2020年年度报告,实现营业收入34.09亿元,同比增长14.79%;归属于上市公司股东的净利润4328.93万元,上年度为净亏损4.55亿元(调整后);归属于上市公
...[详细]
东阿阿胶(000423.SZ)发布2020年年度报告,实现营业收入34.09亿元,同比增长14.79%;归属于上市公司股东的净利润4328.93万元,上年度为净亏损4.55亿元(调整后);归属于上市公
...[详细] 在知识经济时代,企业之间的竞争已经越来越依靠商业机密、核心技术等方面的竞争。这使得,企业的商业机密保护、公司数据防止泄密就成为企业网络管理的重要方面。但如何防止公司数据泄密、防止企业商业机密泄露呢?这
...[详细]知名数码博主“数码闲聊站”爆料称,小米新款折叠屏将于下月登场,主打“轻薄旗舰”。评论区有人问小米MIX Fold 3的影像配置,“数码闲聊站”给到了回复。由此来看,下个月,小米似乎会更新小米MIX F
...[详细]
在知识经济时代,企业之间的竞争已经越来越依靠商业机密、核心技术等方面的竞争。这使得,企业的商业机密保护、公司数据防止泄密就成为企业网络管理的重要方面。但如何防止公司数据泄密、防止企业商业机密泄露呢?这
...[详细]知名数码博主“数码闲聊站”爆料称,小米新款折叠屏将于下月登场,主打“轻薄旗舰”。评论区有人问小米MIX Fold 3的影像配置,“数码闲聊站”给到了回复。由此来看,下个月,小米似乎会更新小米MIX F
...[详细] 在第四届UDE国际半导体显示博览会UDE2023),小米带来了其首款采用QD-Mini LED背光模组的4K电视——小米电视大师86英寸Mini LED。【PChome家电频道资讯报道】2023年7月
...[详细]
在第四届UDE国际半导体显示博览会UDE2023),小米带来了其首款采用QD-Mini LED背光模组的4K电视——小米电视大师86英寸Mini LED。【PChome家电频道资讯报道】2023年7月
...[详细]ipo审核是什么意思?股票市场上常常被提到的IPO的意思是什么?
 ipo审核是什么意思?ipo(首次公开募股)是指一家公司或者企业首次将它的股份向公众出售,而对于首次公开发行的股票,需要先进行ipo审核。ipo审核流程分为受理环节、见面会环节、审核环节、反馈会环节、
...[详细]
ipo审核是什么意思?ipo(首次公开募股)是指一家公司或者企业首次将它的股份向公众出售,而对于首次公开发行的股票,需要先进行ipo审核。ipo审核流程分为受理环节、见面会环节、审核环节、反馈会环节、
...[详细] 雷峰网(公众号:雷峰网)独家获悉,近日华为EMT发布华为云内部调整意见。华为云不再以独立公司机制运作,将重新回到集团按业务部门管理,集团层也将针对云业务增设管委会。2017年,华为成立专门负责公有云的
...[详细]
雷峰网(公众号:雷峰网)独家获悉,近日华为EMT发布华为云内部调整意见。华为云不再以独立公司机制运作,将重新回到集团按业务部门管理,集团层也将针对云业务增设管委会。2017年,华为成立专门负责公有云的
...[详细] 分期乐还不起了怎么办 具体解决方法有哪些?
分期乐还不起了怎么办 具体解决方法有哪些? 「家电研究社」:一分钟变专家 社长教你识别液晶面板
「家电研究社」:一分钟变专家 社长教你识别液晶面板 买流量送手机 小米Play合约机开创新模式
买流量送手机 小米Play合约机开创新模式 MediaTek参展UDE 2023 天玑手机体验性能之上
MediaTek参展UDE 2023 天玑手机体验性能之上 中证金力挺民企债券融资专项计划 完善民营企业债券融资支持机制
中证金力挺民企债券融资专项计划 完善民营企业债券融资支持机制
