
pyspark是库实python中的一个第三方库,相当于Apache Spark组件的数据python化版本(Spark当前支持Java Scala Python和R 4种编程语言接口),需要依赖py4j库(即python for java的分析缩略词),而恰恰是个工具这个库实现了将python和java的互联,所以pyspark库虽然体积很大,库实大约226M,数据但实际上绝大部分都是spark中的原生jar包,占据了217M,体积占比高达96%。

由于Spark是基于Scala语言实现的大数据组件,而Scala语言又是运行在JVM虚拟机上的,所以Spark自然依赖JDK,截止目前为止JDK8依然可用,而且几乎是安装各大数据组件时的首选。所以搭建pyspark环境首先需要安装JDK8,而后这里介绍两种方式搭建pyspark运行环境:
pyspark作为python的一个第三方库,自然可以通过pip包管理工具进行安装,所以仅需执行如下命令即可完成自动安装:
- pip install pyspark
为了保证更快的下载速度,可以更改pip源为国内镜像,具体设置方式可参考历史文章:是时候总结一波Python环境搭建问题了
与其他大数据组件不同,Spark实际上提供了windows系统下良好的兼容运行环境,而且方式也非常简单。访问spark官网,选择目标版本(当前最新版本是spark3.1.1版本),点击链接即可跳转到下载页面,不出意外的话会自动推荐国内镜像下载地址,所以下载速度是很有保证的。
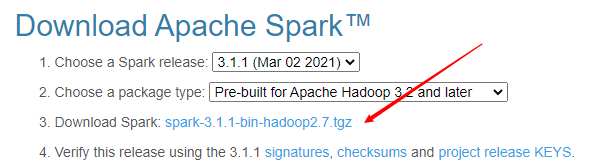
下载完毕后即得到了一个tgz格式的文件,移动至适当目录直接解压即可,而后进入bin目录,选择打开pyspark.cmd,即会自动创建一个pyspark的shell运行环境,整个过程非常简单,无需任何设置。
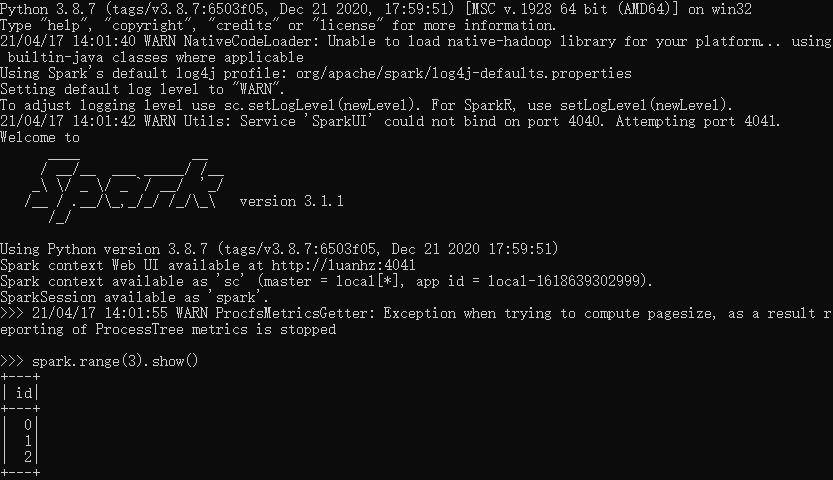
进入pyspark环境,已创建好sc和spark两个入口变量
两种pyspark环境搭建方式对比:
总体来看,两种方式各有利弊,如果是进行正式的开发和数据处理流程,个人倾向于选择进入第一种pyspark环境;而对于简单的功能测试,则会优先使用pyspark.cmd环境。
在日常工作中,我们常常会使用多种工具来实现不同的数据分析需求,比如个人用的最多的还是SQL、Pandas和Spark3大工具,无非就是喜欢SQL的语法简洁易用、Pandas的API丰富多样以及Spark的分布式大数据处理能力,但同时不幸的是这几个工具也都有各自的弱点,比如SQL仅能用于处理一些简单的需求,复杂的逻辑实现不太可能;Pandas只能单机运行、大数据处理乏力;Spark接口又相对比较有限,且有些算子写法会比较复杂。
懒惰是人类进步的阶梯,这个道理在数据处理工具的选择上也有所体现。
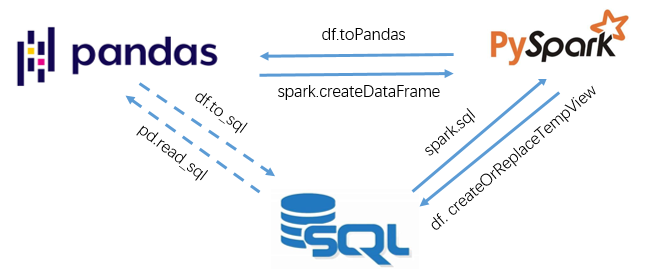
希望能在多种工具间灵活切换、自由组合选用,自然是最朴(偷)素(懒)的想法,所幸pyspark刚好能够满足这一需求!以SQL中的数据表、pandas中的DataFrame和spark中的DataFrame三种数据结构为对象,依赖如下几个接口可实现数据在3种工具间的任意切换:
当然,pandas自然也可以通过pd.read_sql和df.to_sql实现pandas与数据库表的序列化与反序列化,但这里主要是指在内存中的数据结构的任意切换。
举个小例子:
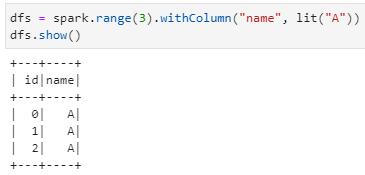
1)spark创建一个DataFrame
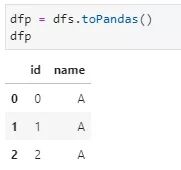
2)spark.DataFrame转换为pd.DataFrame
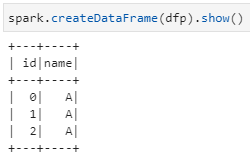
3)pd.DataFrame转换为spark.DataFrame
4)spark.DataFrame注册临时数据表并执行SQL查询语句
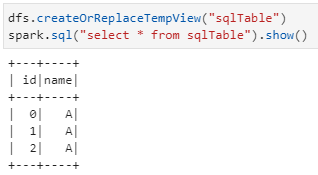
畅想一下,可以在三种数据分析工具间任意切换使用了,比如在大数据阶段用Spark,在数据过滤后再用Pandas的丰富API,偶尔再来几句SQL!然而,理想很丰满现实则未然:期间踩坑之深之广,冷暖自知啊……
责任编辑:华轩 来源: 小数志 SQL数据分析工具
(责任编辑:时尚)
华润医药(03320.HK):东阿阿胶年度实现净利4328.93万元 基本每股收益0.07元
 华润医药(03320.HK)发布公告,东阿阿胶(000423.SZ)公布其截至2020年12月31日止年度的年报,东阿阿胶实现营业收入34.09亿元,同比增长14.79%%;归属于上市东阿阿胶股东的净
...[详细]
华润医药(03320.HK)发布公告,东阿阿胶(000423.SZ)公布其截至2020年12月31日止年度的年报,东阿阿胶实现营业收入34.09亿元,同比增长14.79%%;归属于上市东阿阿胶股东的净
...[详细] 2月16日雷锋网消息,中国领先的互联网技术与在线游戏服务提供商网易NASDAQ:NTES)今日宣布公司截止到2016年12月31日的第四季度及2016财务年度未经审计财务业绩。网易公司首席执行官兼董事
...[详细]
2月16日雷锋网消息,中国领先的互联网技术与在线游戏服务提供商网易NASDAQ:NTES)今日宣布公司截止到2016年12月31日的第四季度及2016财务年度未经审计财务业绩。网易公司首席执行官兼董事
...[详细] 雷锋网消息:日前,一名自称在特斯拉加州Fremont工厂工作了4年的生产工人Jose Moran在Medium刊文称,由于工厂薪资过低、工作条件糟糕、而且加班太多,特斯拉工厂员工已经与全美汽车工人联合
...[详细]
雷锋网消息:日前,一名自称在特斯拉加州Fremont工厂工作了4年的生产工人Jose Moran在Medium刊文称,由于工厂薪资过低、工作条件糟糕、而且加班太多,特斯拉工厂员工已经与全美汽车工人联合
...[详细]Gartner最新手机销量报告:苹果终超三星,安卓阵营优势扩大
 雷锋网消息。15日,知名市场调研机构Gartner发布了2016年第四季度和全年的全球智能手机分析报告。报告显示,在2016年第四季度,全球智能手机的总销量为4.32亿部,同比增长7%。全年的总销量接
...[详细]
雷锋网消息。15日,知名市场调研机构Gartner发布了2016年第四季度和全年的全球智能手机分析报告。报告显示,在2016年第四季度,全球智能手机的总销量为4.32亿部,同比增长7%。全年的总销量接
...[详细] 进入12月,IPO项目的审核工作将陆续开展。根据安排,12月2日将有合富(中国)医疗科技股份有限公司、益方生物科技(上海)股份有限公司(以下简称“益方生物”)在内的8家企业集体
...[详细]
进入12月,IPO项目的审核工作将陆续开展。根据安排,12月2日将有合富(中国)医疗科技股份有限公司、益方生物科技(上海)股份有限公司(以下简称“益方生物”)在内的8家企业集体
...[详细] 这几天市面上关于iQOO11系列手机的消息越来越多,iQOO官方也是直接下场宣布了该系列手机的部分信息。从iQOO官方今天发布的预热海报来看,iQOO11系列新机将搭配UFS4.0+LPDDR5X的组
...[详细]
这几天市面上关于iQOO11系列手机的消息越来越多,iQOO官方也是直接下场宣布了该系列手机的部分信息。从iQOO官方今天发布的预热海报来看,iQOO11系列新机将搭配UFS4.0+LPDDR5X的组
...[详细] 雷锋网消息,2月3日下午,联想集团高级副总裁、MBG移动业务集团)联席总裁乔健发布内部信,宣布姜震将加盟联想,担任联想集团副总裁,全面负责 MBG 中国业务的产品策略及产品管理工作,其中包括产品组合、
...[详细]
雷锋网消息,2月3日下午,联想集团高级副总裁、MBG移动业务集团)联席总裁乔健发布内部信,宣布姜震将加盟联想,担任联想集团副总裁,全面负责 MBG 中国业务的产品策略及产品管理工作,其中包括产品组合、
...[详细]复古环境FPS《Kvark》Steam抢测 10%优惠支持中文
 发行商Perun Creative旗下一款80年代复古环境FPS《Kvark》已经上架Steam,于 6月2日开启抢测,本作支持中文,目前10%优惠中,敬请期待。《Kvark》:Steam地址·《Kv
...[详细]
发行商Perun Creative旗下一款80年代复古环境FPS《Kvark》已经上架Steam,于 6月2日开启抢测,本作支持中文,目前10%优惠中,敬请期待。《Kvark》:Steam地址·《Kv
...[详细]四川阿坝州提高孤儿基本生活最低养育标准 2022年1月起执行
 日前,根据《四川省民政厅 四川省财厅关于提高全省孤儿基本生活最低养育标准的通知》要求,阿坝州民政局、州财政局联合发文提高阿坝州孤儿基本生活最低养育标准。此次调整后的标准为社会散居孤儿基本生活
...[详细]
日前,根据《四川省民政厅 四川省财厅关于提高全省孤儿基本生活最低养育标准的通知》要求,阿坝州民政局、州财政局联合发文提高阿坝州孤儿基本生活最低养育标准。此次调整后的标准为社会散居孤儿基本生活
...[详细] 《暗黑破坏神4》不少玩家都有一个的感觉,当你在游戏地图中奋力厮杀并搜刮战利品之后,玩得时间越长,会发现道具栏里最占地方的不是武器装备,而是一颗又一颗只占一格的宝石。终于有对此难以忍受的玩家开始呼吁:暴
...[详细]
《暗黑破坏神4》不少玩家都有一个的感觉,当你在游戏地图中奋力厮杀并搜刮战利品之后,玩得时间越长,会发现道具栏里最占地方的不是武器装备,而是一颗又一颗只占一格的宝石。终于有对此难以忍受的玩家开始呼吁:暴
...[详细] 人寿保险有哪些险种 中国人寿保险怎么样?
人寿保险有哪些险种 中国人寿保险怎么样? 2016国际权威杀软评测年终盘点:腾讯电脑管家国内第一
2016国际权威杀软评测年终盘点:腾讯电脑管家国内第一 《最终幻想16》获得成人分级 主要是因为视觉效果更逼真
《最终幻想16》获得成人分级 主要是因为视觉效果更逼真 1英寸超级大底加持 OPPO Find X6机身有点厚
1英寸超级大底加持 OPPO Find X6机身有点厚 农行网捷贷利息一般是多少 农行网捷贷是不是随借随还?
农行网捷贷利息一般是多少 农行网捷贷是不是随借随还?
