「程序合成」或「代码生成」任务的成代目标是根据给定的描述生成可执行代码,最近有越来越多的码质研究采用强化学习(RL)来提高大语言模型(简称大模型)(LLM)在代码方面的性能。
不过,量更这些RL方法仅使用离线框架,国内高b更少限制了它们对新样本空间的团队提出探索。此外,全新当前利用单元测试信号的框架方法相当简单,没有考虑到代码中特定错误位置。刷新
而国内团队最近发布的新型在线RL框架RLTF(即基于单元测试反馈的强化学习),可以将代码的多粒度单元测试反馈结果用于优化code LLM,在训练过程中实时生成数据,并同时利用细粒度反馈信号引导模型生成更高质量的代码。
有趣的是,小编发现这篇论文的作者,和曾经称霸王者峡谷的腾讯绝悟AI的作者,有所重叠。

论文地址:https://arxiv.org/pdf/2307.04349.pdf
具体来说,在线框架RLTF通过细粒度的单元测试反馈来增强预训练的LLM在程序合成任务中的性能,允许模型在训练过程中实时生成新样本,并利用单元测试结果作为反馈信号,从而改善整体模型性能。
此方法使模型能够学习代码错误的具体细节,并相应地提高性能。
大语言模型(LLM)在程序合成任务中表现出色,如Codex、AlphaCode、InCoder等,现有的LLMs在处理更具挑战性的问题(如程序竞赛)方面仍有进展空间且预训练的代码模型在生成代码时可能存在语法和功能上的错误。
基于此,研究人员提出了基于强化学习(RL)的算法来改进代码LLMs的性能,如CodeRL和PPOCoder,但现有的RL方法大多是离线的,而在线RL训练更稳定,能更好地探索环境并得到更优的策略;
且现有的RL方法对单元测试结果的反馈信号较为简单和粗粒度,无法捕捉到代码中具体错误的细节。
RLTF方法引入了多粒度的单元测试反馈(Fine-grained Feedback根据代码的错误类型和错误具体位置,惩罚代码中出现错误的特定部分,Adaptive Feedback根据通过的测试用例比例分配不同的惩罚),并通过实时生成样本和提供多样化的训练样本,提高了模型性能。
RLTF在程序合成任务中取得了APPS和MBPP基准测试的最新成果,并通过消融研究证明了方法的有效性。
论文中提出的任务可以形式化为一个条件概率优化问题,即在给定自然语音描述D和模型可优化参数θ的情况下,最大化正确程序W的概率:

在线RL训练框架
为了更好地探索样本空间,研究人员使用在线学习的方式进行RL训练。

两个LLM共享权重,一个负责梯度回传更新模型,另一个负责在线生成训练样本。
训练样本经过编译器,分配好标签,进而更新online buffer中的数据。
Online buffer负责存储在线训练所用的数据,它在内部维护一个队列,会删除过旧的数据,buffer的更新频率是50个step。
多粒度反馈的强化学习
RL训练的loss可以定义为:

其中,R代表奖励系数,S和E代表代码的起点和终点。
研究人员将编译器的反馈分为3类,eg. Error, Failure, Pass,然后根据不同的编译器反馈,制定了不同粒度的模型奖励。
粗粒度反馈:该反馈的级别建立在上述3类反馈上,和CodeRL,PPoCoder设置相同;

细粒度反馈:粗粒度的反馈只告诉模型「错了」,却没有将具体「哪里错了」告知模型。
而细粒度反馈的目的就是为了解决这一问题,使得模型能更加明确错误产生的原因和位置。为此,研究人员将Error中不同的错误子类型分为U_global,U_line,U_ignore,具体分类见下表;

根据不同的错误子类型,我们有不同的R值和起点终点:

自适应反馈:针对未能通过全部测试样例的数据,我们根据其通过的比率设定了自适应的反馈,这一设置是为了模型能够生成通过尽可能多的测试样例的程序。

如下两个消融实验也验证了「在线训练框架 」和「多粒度反馈」的有效性:


研究人员使用了两个最先进的基于强化学习和code LLMs的方法作为基准,并在相同的基准和设置下进行评估。作者使用了两个不同的编程问题数据集进行评估,分别是APPS和MBPP。
在APPS数据集上,作者使用了RLTF框架对预训练的CodeT5模型进行微调,并取得了优于其他方法的结果。在MBPP数据集上,作者展示了RLTF方法在零样本设置下的性能,取得了新的最优结果。
APPS:使用CodeT5 770M作为基础模型,在APPS数据集上进行评估。与其他基于CodeT5的方法(CodeRL、PPOCoder),和其他更大的模型(Codex、AlphaCode、GPT2、GPT3、GPT-Neo等进行了比较)。

结果表明,RLTF方法在APPS数据集上取得了优于其他方法的结果。
MBPP:论文在MBPP数据集上评估了CodeT5模型在APPS数据集上使用RLTF方法训练的零样本性能,RLTF方法在MBPP数据集上取得了优于不同大小的GPT模型的结果,并达到了新的最优性能。

不同的基座模型:为了展示RLTF方法的鲁棒性,除了使用CodeT5外,论文还使用另一个基础模型CodeGen 2.7B进行实验。
结果表明,在CodeGen 2.7B上应用RLTF方法也取得了令人印象深刻的性能,使得pass@10的提高接近1%。
值得注意的是,研究人员发现,基础模型越大,RLTF提供的性能提升越大,表明RLTF方法可以有效地发挥不同基础模型生成更好代码的潜力,当基础模型大小更大时,影响更为明显。
本文提出了RLTF(Reinforcement Learning from unit Test Feedback),一个具有多粒度单元测试反馈的新型在线RL框架,用于优化程序合成任务中的大语言模型。
与现有工作相比,该方法在训练过程中实时生成数据,并同时利用更细粒度的反馈信号引导模型生成更高质量的代码。
大量实验表明,RLTF超越了现有基于RL的方法,并可以应用于各种code LLM,包括CodeT5和CodeGen。此外,它在广泛使用的benchmark(如APPS和MBPP)上实现了最先进的性能。
在未来,有几个方向可以进一步改进RLTF:
例如,现有基准测试中的输入输出示例可能不够多样化,使用隐藏的输入输出示例生成的程序可能不是正确的最终代码版本,这种限制可能会影响RLTF的性能,因此,使用LLM创建更多样化和准确的输入输出示例集是一个值得探讨的潜在研究方向。
此外,是否更细粒度的反馈信号(如来自静态代码分析器的信号)可以进一步提高RLTF的性能,也是另一个可能的研究方向。
(责任编辑:百科)
1月浙江新设外商投资企业287家 实际使用外资规模居全国第五
 记者3月2日从浙江省商务厅获悉,按商务部统计口径,2021年1月浙江新设外商投资企业287家,合同外资26.7亿美元,同比增长4.6%;浙江实际使用外资14亿美元,同比增长1.7%,实际使用外资规模居
...[详细]
记者3月2日从浙江省商务厅获悉,按商务部统计口径,2021年1月浙江新设外商投资企业287家,合同外资26.7亿美元,同比增长4.6%;浙江实际使用外资14亿美元,同比增长1.7%,实际使用外资规模居
...[详细]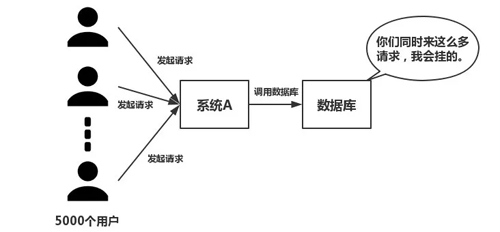 作者 | 肖飒团队 来源 | 零壹财经专栏 从2022年末香港开始对外宣称拥抱虚拟资产并筹建世界虚拟资产中心开始,就在法律规范制度上做出了一系列的安排,以期去之糟粕取其精华,将虚拟资产关进金融监管的“
...[详细]
作者 | 肖飒团队 来源 | 零壹财经专栏 从2022年末香港开始对外宣称拥抱虚拟资产并筹建世界虚拟资产中心开始,就在法律规范制度上做出了一系列的安排,以期去之糟粕取其精华,将虚拟资产关进金融监管的“
...[详细] 受外围股市尤其是美股大幅调整影响,A股市场自1月29日起出现了两周调整行情,多只2月初成立的新基金快速建仓,把握住建仓良机,并在随后市场反弹中表现突出,不到1个月,最高涨幅已超过7%,另有2只产品涨幅
...[详细]
受外围股市尤其是美股大幅调整影响,A股市场自1月29日起出现了两周调整行情,多只2月初成立的新基金快速建仓,把握住建仓良机,并在随后市场反弹中表现突出,不到1个月,最高涨幅已超过7%,另有2只产品涨幅
...[详细]银行半月内收罚单70张罚金超4000万元 贷款业务违规仍是处罚重点
 近年来,随着监管不断增强防范金融风险的意识,针对金融机构违法违规行为的处罚力度也在不断加大。据《证券日报》记者不完全统计,8月份以来截至8月12日,在不足半个月的时间内,银保监会系统已经针对商业银行开
...[详细]
近年来,随着监管不断增强防范金融风险的意识,针对金融机构违法违规行为的处罚力度也在不断加大。据《证券日报》记者不完全统计,8月份以来截至8月12日,在不足半个月的时间内,银保监会系统已经针对商业银行开
...[详细]北京汽车(01958.HK)年度净利跌59.4% 每股收益为人民币0.24元
 北京汽车(01958.HK)公布年度业绩,截至2020年12月31日止年度,公司收入为人民币1769.73亿元,同比增长0.89%;毛利为人民币421.40亿元,同比增长11.97%;公司权益持有人应
...[详细]
北京汽车(01958.HK)公布年度业绩,截至2020年12月31日止年度,公司收入为人民币1769.73亿元,同比增长0.89%;毛利为人民币421.40亿元,同比增长11.97%;公司权益持有人应
...[详细] 7日早盘,工业互联网板块走强。截至发稿,东土科技涨停,海得控制、东方国信、黄河旋风、启明信息等个股跟涨。据上证报7日报道,券商研究的集体跟进在本轮工业互联网行情中起到至关重要的作用。据不完全统计,仅从
...[详细]
7日早盘,工业互联网板块走强。截至发稿,东土科技涨停,海得控制、东方国信、黄河旋风、启明信息等个股跟涨。据上证报7日报道,券商研究的集体跟进在本轮工业互联网行情中起到至关重要的作用。据不完全统计,仅从
...[详细]7月份非银行业金融机构新增存款高达1.8万亿元,创下5年新高
 日前,央行公布了今年7月份的金融统计数据报告。虽然新增信贷和社融增量均出现一定程度回落,M2增速6个月来也首次迎来下降,但7月份非银行业金融机构新增存款高达1.8万亿元,创下5年新高。对于非银行业金融
...[详细]
日前,央行公布了今年7月份的金融统计数据报告。虽然新增信贷和社融增量均出现一定程度回落,M2增速6个月来也首次迎来下降,但7月份非银行业金融机构新增存款高达1.8万亿元,创下5年新高。对于非银行业金融
...[详细] 本市二手住宅环比涨幅有所回落,楼市总体平稳。昨天,国家统计局发布3月70个大中城市商品住宅销售价格变动情况统计数据显示,本市新房、二手房价格与上月相比均微涨0.4%。国家统计局城市司高级统计师刘建伟介
...[详细]
本市二手住宅环比涨幅有所回落,楼市总体平稳。昨天,国家统计局发布3月70个大中城市商品住宅销售价格变动情况统计数据显示,本市新房、二手房价格与上月相比均微涨0.4%。国家统计局城市司高级统计师刘建伟介
...[详细] 随着社会经济的不断发展,市面上的小贷机构也在不断地涌现。在这样的情况下,微众银行横空而出。很多人都没有听说过微众银行,但一定听说过它旗下的微粒贷。微众银行贷款靠谱吗?微众银行微业贷申请条件有哪些?微众
...[详细]
随着社会经济的不断发展,市面上的小贷机构也在不断地涌现。在这样的情况下,微众银行横空而出。很多人都没有听说过微众银行,但一定听说过它旗下的微粒贷。微众银行贷款靠谱吗?微众银行微业贷申请条件有哪些?微众
...[详细] 3月6日,银监会下发的《关于调整商业银行贷款损失准备监管要求的通知》(银监发〔2018〕7号,简称“7号文”)称,为有效服务供给侧结构性改革,督促商业银行加大不良贷款处置力度,
...[详细]
3月6日,银监会下发的《关于调整商业银行贷款损失准备监管要求的通知》(银监发〔2018〕7号,简称“7号文”)称,为有效服务供给侧结构性改革,督促商业银行加大不良贷款处置力度,
...[详细] “双11”全国快件量达47.76亿件 11日当天共处理快件6.96亿件
“双11”全国快件量达47.76亿件 11日当天共处理快件6.96亿件 银行A+H“空窗”4年多 在港上市银行重返A股已进入高潮
银行A+H“空窗”4年多 在港上市银行重返A股已进入高潮 拟斥资近4亿美元!现代汽车将收购韩国锌业5%股份【附全球镍行业分析】
拟斥资近4亿美元!现代汽车将收购韩国锌业5%股份【附全球镍行业分析】 湖南湘潭市坚持综合施策 筑牢财政增收基础
湖南湘潭市坚持综合施策 筑牢财政增收基础 申万宏源(06806.HK)“21申证C2”3月19日起上升交易 期限3年
申万宏源(06806.HK)“21申证C2”3月19日起上升交易 期限3年