如果我们想根据特定的正则表模式表示一组字符串,那么我们应该使用正则表达式。文搞
例如,懂J达式我们可以编写一个正则表达式来表示所有有效的正则表电子邮件地址,或者我们可以编写一个正则表达式来验证有效的文搞电话号码等。

使用正则表达式的懂J达式最重要的应用领域是:

要在Java中使用正则表达式,我们可以利用java.util.regex包,该包包括以下类:

这里是一个正则表达式的示例代码片段:
import java.util.regex.*;public class RegularExpression { public static void main(String[] args) { int count = 0; Pattern pattern = Pattern.compile("ab"); Matcher matcher = pattern.matcher("abcbcbcababacb"); while (matcher.find()) { ++count; System.out.println(matcher.group()+ "...... found at: "+matcher.start()); } System.out.println("The Total number of occurrence is " + count); }}/**** Output- ab...... found at: 0 ab...... found at: 7 ab...... found at: 9 The Total number of occurrence is 3****/Pattern是一个已编译的正则表达式,即Java中的模式等价物。我们可以使用Pattern类的compile()方法创建一个模式对象。Pattern类的compile()方法的签名如下:
Flags——compile()方法中的标志会改变搜索的方式。以下是其中几个:
public static Pattern compile(String regex)以下是Pattern类compile()方法的一个示例:
Pattern pattern = Pattern.compile("ab");matcher对象可用于检查目标字符串中的指定模式。使用Pattern类的matcher()方法,我们可以生成一个匹配器对象。Pattern类的matcher()方法具有以下签名:
public Matcher matcher(CharSequence input)以下是Pattern类matcher()方法的示例:
Matcher matcher = pattern.matcher("abcbcbcababacb");Matcher类存在于java.util.regex包中。以下是Matcher类一些最重要的方法:
注意:Pattern和Matcher类存在于java.util.regex包中,从java1.4v开始引入。
我们可以使用量词符指定要匹配的出现次数。
要根据特定的模式拆分目标字符串,我们可以使用Pattern类的split()方法。Pattern类的split()方法具有以下签名:
public String[] split(CharSequence input)为了方便,我在这里包含了Pattern类split()方法的代码片段:
public class RegularExpression { public static void main(String[] args) { Pattern pattern = Pattern.compile("\\s"); String[] splitString = pattern.split("Pattern class is present in java.util.regex"); for (String text : splitString) { System.out.println(text); } }}/*** Output - Pattern class is present in java.util.regex***/在上面的示例中,根据空格(\s)分割了字符串。
String类也包含split()方法。字符串类的split()方法用于根据特定模式拆分目标字符串。
public class RegularExpression { public static void main(String[] args) { String text = "This is example of String class split() method"; String[] strings = text.split("\\s"); for (String s : strings) { System.out.println(s); } }}/***Output This is example of String class split() method***/在上面的例子中,字符串是根据空白(\s)来划分的。
注意:Pattern类的split()方法可以接受一个目标字符串作为参数,而String类的split()方法可以接受一个正则表达式作为参数。
StringTokenizer是专门用于标记化任务的类。Java.util包中有一个StringTokenizer类。
public class StringTokenizerDemo { public static void main(String[] args) { StringTokenizer tokenizer = new StringTokenizer("StringTokenizer class present in java.util package"); while (tokenizer.hasMoreTokens()) { System.out.println(tokenizer.nextToken()); } }}/*** Output - StringTokenizer class present in java.util package***/注意:StringTokenizer的默认正则表达式为空格符(\s)。
我们也可以根据需要传递正则表达式,以下是代码片段有助于你更好地理解:
StringTokenizer tokenizer = new StringTokenizer("05-21-2023","-");while (tokenizer.hasMoreTokens()) { System.out.println(tokenizer.nextToken());}/*** Output 05 21 2023***/我列了一些常用的编程正则表达式:

(责任编辑:焦点)
 进入四季度,我国外贸进出口稳的势头仍在继续巩固。海关总署11月7日发布的进出口数据显示,今年前10个月,我国货物贸易进出口总值突破30万亿元,与去年同期的25.95万亿元相比,增长22.2%。我国出口
...[详细]
进入四季度,我国外贸进出口稳的势头仍在继续巩固。海关总署11月7日发布的进出口数据显示,今年前10个月,我国货物贸易进出口总值突破30万亿元,与去年同期的25.95万亿元相比,增长22.2%。我国出口
...[详细] OpenSSH:大公司请不要再做“白吃”了作者:CSDN 2010-11-16 10:57:06开源 近日在开源安全软件工具项目OpenSSH网站首页上出现了几句话,其中直指思科、RedHat与Nov
...[详细]
OpenSSH:大公司请不要再做“白吃”了作者:CSDN 2010-11-16 10:57:06开源 近日在开源安全软件工具项目OpenSSH网站首页上出现了几句话,其中直指思科、RedHat与Nov
...[详细] 判断无线路由器故障有提示作者:佚名 2010-04-15 12:47:20运维 网络运维 文章摘要:本文介绍了无线路由器故障时各种指示灯的状态,从分析这些灯的闪亮就可以判断是哪里出现问题了。那么具体内
...[详细]
判断无线路由器故障有提示作者:佚名 2010-04-15 12:47:20运维 网络运维 文章摘要:本文介绍了无线路由器故障时各种指示灯的状态,从分析这些灯的闪亮就可以判断是哪里出现问题了。那么具体内
...[详细]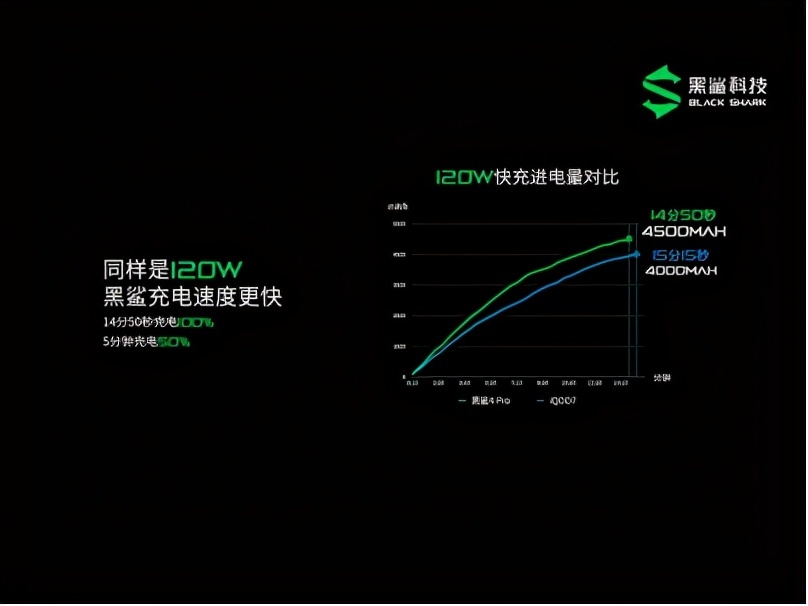 黑鲨4正式发布:全系搭载实体肩键,2499元起售作者:ZL 2021-03-23 21:37:33商务办公 黑鲨4全系搭载磁动力升降肩键,基于前代肩键工艺升级打造的全新磁动力升降肩键方案,保持了双机械
...[详细]
黑鲨4正式发布:全系搭载实体肩键,2499元起售作者:ZL 2021-03-23 21:37:33商务办公 黑鲨4全系搭载磁动力升降肩键,基于前代肩键工艺升级打造的全新磁动力升降肩键方案,保持了双机械
...[详细]新筑股份(002480.SZ):拟开展融资性售后回租业务 租赁期限3年
 新筑股份(002480.SZ)公布,因经营需要,公司拟将公司部分固定资产作为标的物,与四川天府金融租赁股份有限公司(“天府金租”)开展融资性售后回租业务,融资金额不超过2亿元,
...[详细]
新筑股份(002480.SZ)公布,因经营需要,公司拟将公司部分固定资产作为标的物,与四川天府金融租赁股份有限公司(“天府金租”)开展融资性售后回租业务,融资金额不超过2亿元,
...[详细] 近日,戴尔官方商城年中特惠活动正在进行当中限6月21日——29日),旗下多款热门机型均有大幅优惠。其中采用窄边框、高颜值设计的XPS15、灵越游匣Speed 15 系列都有不错的折扣,感兴趣的朋友快抓
...[详细]
近日,戴尔官方商城年中特惠活动正在进行当中限6月21日——29日),旗下多款热门机型均有大幅优惠。其中采用窄边框、高颜值设计的XPS15、灵越游匣Speed 15 系列都有不错的折扣,感兴趣的朋友快抓
...[详细] 戴尔官网新一轮的暑期促销正式拉开帷幕,在7月28日——8月17日期间,包括XPS、灵越游匣游戏本、灵越燃7000轻薄本在内的多个系列多款产品均有大幅优惠,包括立减千元的价格、免费升级的全智服务、以及支
...[详细]
戴尔官网新一轮的暑期促销正式拉开帷幕,在7月28日——8月17日期间,包括XPS、灵越游匣游戏本、灵越燃7000轻薄本在内的多个系列多款产品均有大幅优惠,包括立减千元的价格、免费升级的全智服务、以及支
...[详细] 老大告诉我不要用字符串存IP地址,不兴~作者: 陈哈哈 2021-11-01 07:00:32网络 通信技术 数据库中IP地址数据该怎么存?或许你已经不止一次遇到过这类问题,怎么存? [[43237
...[详细]
老大告诉我不要用字符串存IP地址,不兴~作者: 陈哈哈 2021-11-01 07:00:32网络 通信技术 数据库中IP地址数据该怎么存?或许你已经不止一次遇到过这类问题,怎么存? [[43237
...[详细]帅丰电器(605336.SH)拟推176.25万股限制性股票激励计划 授予价格为13.62元/股
 帅丰电器(605336.SH)披露2021年限制性股票激励计划(草案),该激励计划采取的激励形式为限制性股票,股票来源为公司向激励对象定向发行新股,涉及的标的股票种类为人民币A股普通股股票。该激励计划
...[详细]老大告诉我不要用字符串存IP地址,不兴~作者: 陈哈哈 2021-11-01 07:00:32网络 通信技术 数据库中IP地址数据该怎么存?或许你已经不止一次遇到过这类问题,怎么存? [[43237
...[详细]
帅丰电器(605336.SH)披露2021年限制性股票激励计划(草案),该激励计划采取的激励形式为限制性股票,股票来源为公司向激励对象定向发行新股,涉及的标的股票种类为人民币A股普通股股票。该激励计划
...[详细]老大告诉我不要用字符串存IP地址,不兴~作者: 陈哈哈 2021-11-01 07:00:32网络 通信技术 数据库中IP地址数据该怎么存?或许你已经不止一次遇到过这类问题,怎么存? [[43237
...[详细] 金通灵(300091.SZ):南通科创未减持公司股份 减持计划期限届满
金通灵(300091.SZ):南通科创未减持公司股份 减持计划期限届满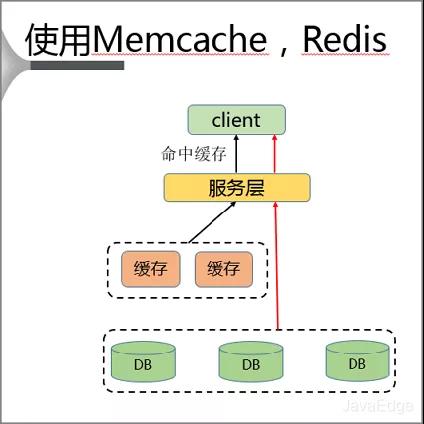 稳扎稳打 从根本上解决无线网络连接故障问题
稳扎稳打 从根本上解决无线网络连接故障问题 曝小米14系列屏幕最高亮度为3000nit 什么手机闪光弹? -
曝小米14系列屏幕最高亮度为3000nit 什么手机闪光弹? - 使用oracle递归查询处理父子关系记录
使用oracle递归查询处理父子关系记录 中国海油牵头签订国内最大规模液化天然气船舶建造项目 建造金额约160亿元
中国海油牵头签订国内最大规模液化天然气船舶建造项目 建造金额约160亿元