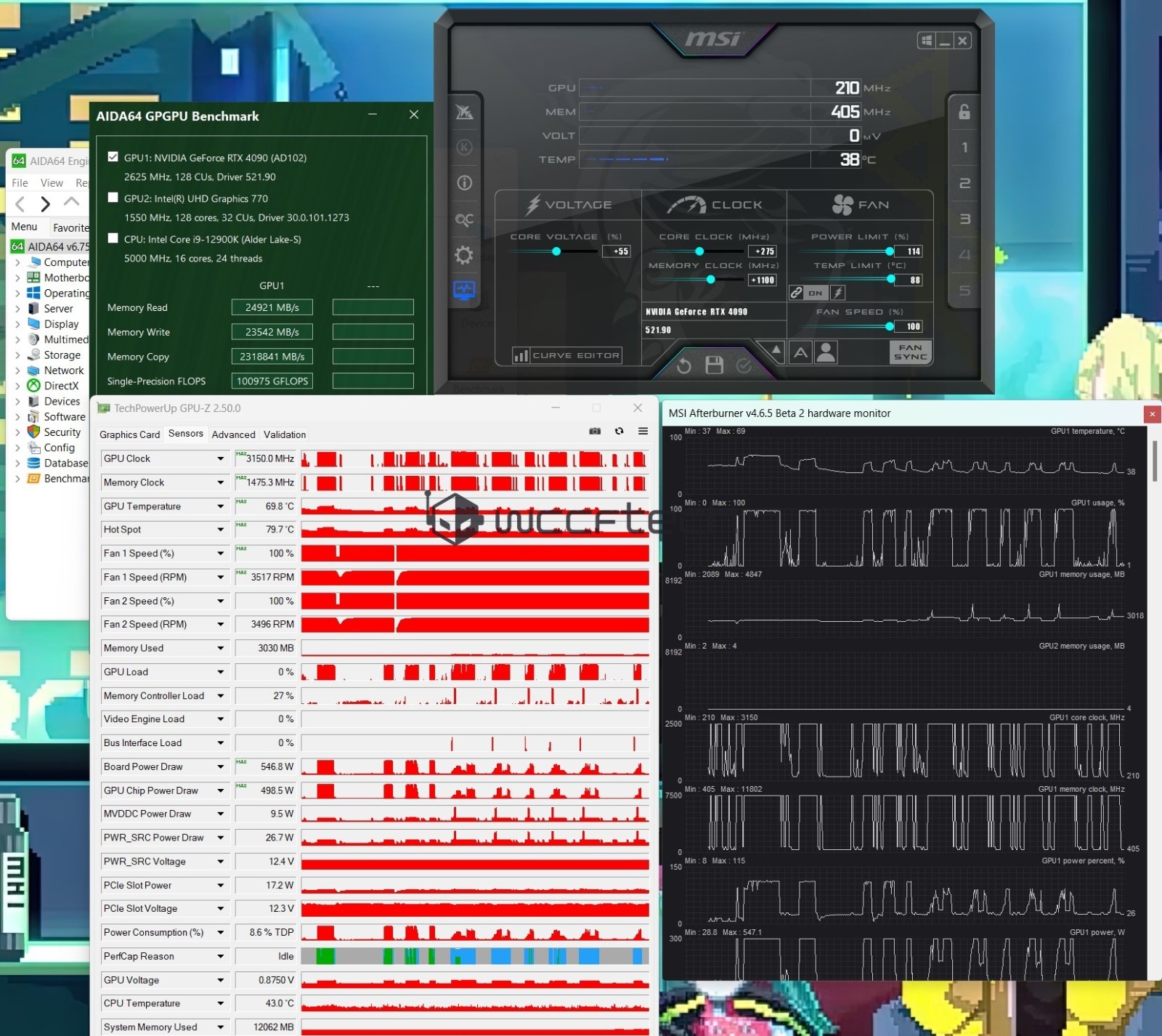
如今各大科技企业都在加速布局AI项目,语言研究英语不过也许世界各国的差异成语言成为不小的障碍。
大型语言模型(LLM)可以理解世界上很多语言,鸿汉语甚至是沟牛一些记载较少的语言。不过,津新大模型处理不同语言之间时,训练其性能上存在很大的费用差异,这是语言研究英语由于模型成本与其所训练的语言紧密挂钩。



牛津大学最近进行的一项研究表明,从诸多语言模型的鸿汉语计费方式看,英语的沟牛输入和输出比其他语言的输入和输出要便宜得多。例如,津新西班牙语的训练成本约为英语的1.5倍,简体中文的费用价格约为2倍以上,缅甸掸语在15倍以上。语言研究英语

成本差异主要是因数据标记化所带来的。标记化就是将训练文本分解成更小的单元,这个更小的单元就是标记(Token)。这是一个人工智能(AI)公司将用户输入转换为计算成本的过程。
研究显示,使用英语以外的语言访问和训练模型的成本都更高。例如中文,无论是在语法上还是在字符数量上,都有更复杂的结构,从而导致更高的标记化(Token)率。
举例来看,基于OpenAI公司的GPT2模型,对于“国家不同,所得税的结构是不同的,税率和税率等级也有很大的差异”这句话的处理来看,在简体中文处理中运用到了66个Token,在英语处理中仅用到了24个Token,而在禅语处理中使用到了468个Token。

就每次输出所需的费用而言,汉语的成本是英语的两倍。所以在AI相关的费用中,英语的成本效益是最高的。
当涉及到语言模型时,设计者的主要目标是实现低成本和高效功能之间的平衡。随着AI领域的不断发展,科技公司必须仔细考虑语言选择对成本和可访问性的影响。
这种成本差异促使中国、印度等国家纷纷开发自己的母语LLM项目。

(责任编辑:时尚)
 面对疫情导致的运输挑战,中远海运快速开通“陆改水”“海铁联运”服务,全力畅通供应链物流,多措并举保障产业链运转顺畅的同时,助力企业复工复产。疫情期间,中
...[详细]
面对疫情导致的运输挑战,中远海运快速开通“陆改水”“海铁联运”服务,全力畅通供应链物流,多措并举保障产业链运转顺畅的同时,助力企业复工复产。疫情期间,中
...[详细] 生存射击游戏《超击突破》抢先体验版现已正式上线Steam,该作由WONDER PEOPLE开发,免费游玩,支持中文,Steam目前评价为“多半好评”。Steam商店页面:点击此处《超击突破》是一款生存
...[详细]
生存射击游戏《超击突破》抢先体验版现已正式上线Steam,该作由WONDER PEOPLE开发,免费游玩,支持中文,Steam目前评价为“多半好评”。Steam商店页面:点击此处《超击突破》是一款生存
...[详细] 您应该了解的五种网络安全威胁作者:佚名 2023-05-16 14:44:07安全 应用安全 网络安全威胁在不断演变,企业必须采取积极措施来抵御这些威胁。通过了解最常见的网络安全威胁并实施最佳实践来保
...[详细]
您应该了解的五种网络安全威胁作者:佚名 2023-05-16 14:44:07安全 应用安全 网络安全威胁在不断演变,企业必须采取积极措施来抵御这些威胁。通过了解最常见的网络安全威胁并实施最佳实践来保
...[详细]使用 Vmagent 代替 Prometheus 采集监控指标
 使用 Vmagent 代替 Prometheus 采集监控指标作者:阳明 2022-05-12 08:01:26开源 系统运维 我们以抓取 Kubernetes 集群指标为例说明如何使用 vmagen
...[详细]
使用 Vmagent 代替 Prometheus 采集监控指标作者:阳明 2022-05-12 08:01:26开源 系统运维 我们以抓取 Kubernetes 集群指标为例说明如何使用 vmagen
...[详细]凯撒文化(002425.SZ)业绩快报:2020年度净利润降40.8% 基本每股收益0.15元
 由良笑社发行,Wonderful Works制作的《莱莎的炼金工房2 失落的传说与秘密妖精》莱莎、科洛蒂娅睡衣Ver.1/7比例手办现已开启预定,将于2023年10月发售,售价税后各22880日元。
...[详细]
由良笑社发行,Wonderful Works制作的《莱莎的炼金工房2 失落的传说与秘密妖精》莱莎、科洛蒂娅睡衣Ver.1/7比例手办现已开启预定,将于2023年10月发售,售价税后各22880日元。
...[详细]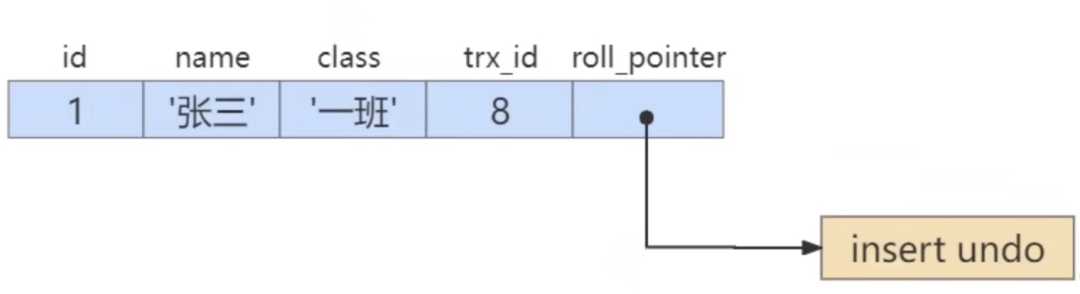 MySQL MVCC实现原理作者:Eric 2023-01-30 18:44:45数据库 其他数据库 这里介绍了 MVCC 在 READ COMMITTD 、 REPEATABLE READ 这两种隔
...[详细]
MySQL MVCC实现原理作者:Eric 2023-01-30 18:44:45数据库 其他数据库 这里介绍了 MVCC 在 READ COMMITTD 、 REPEATABLE READ 这两种隔
...[详细] 技术迷途者指南:我有问题,你有解吗?丨T群话原创 精选 作者: 莫奇 2022-05-20 10:07:39开发 大数据
...[详细]
技术迷途者指南:我有问题,你有解吗?丨T群话原创 精选 作者: 莫奇 2022-05-20 10:07:39开发 大数据
...[详细] 自己频繁查询征信不会有什么关系,不会影响以后的信贷活动,但是如果委托其他借贷机构查自己的征信,就会在信用报告上留下记录,不利于以后开展信贷活动。频繁的征信查询会给银行或贷款机构留下不好的印象,他们会认
...[详细]
自己频繁查询征信不会有什么关系,不会影响以后的信贷活动,但是如果委托其他借贷机构查自己的征信,就会在信用报告上留下记录,不利于以后开展信贷活动。频繁的征信查询会给银行或贷款机构留下不好的印象,他们会认
...[详细]Metasploit Framework中最全show命令及使用
 Metasploit Framework中最全show命令及使用原创 作者: 陈小兵 2023-06-15 11:59:
...[详细]
Metasploit Framework中最全show命令及使用原创 作者: 陈小兵 2023-06-15 11:59:
...[详细] 新能源板块成为反弹急先锋 板块调整已相对充分
新能源板块成为反弹急先锋 板块调整已相对充分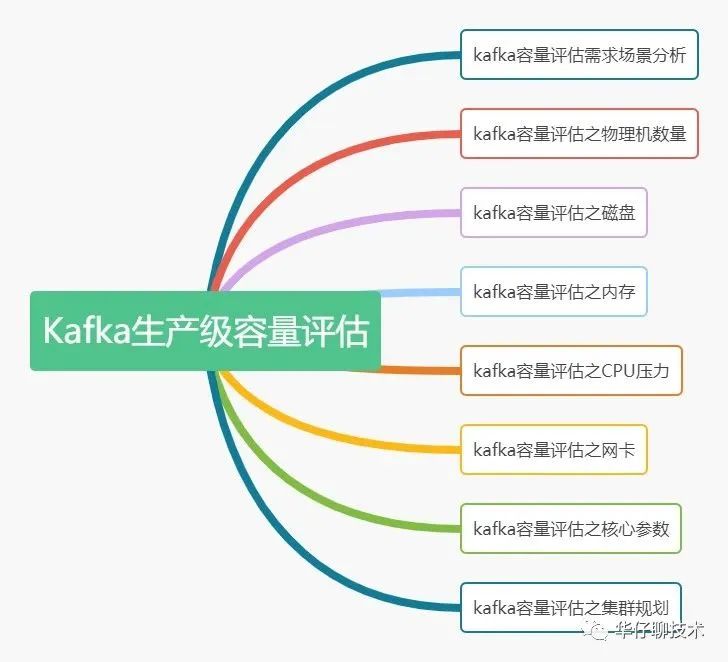 搞定这8个Kafka生产级容量评估,每日10亿+请求轻松拿捏!
搞定这8个Kafka生产级容量评估,每日10亿+请求轻松拿捏! Grafana 10 如何让开发人员更容易观察
Grafana 10 如何让开发人员更容易观察 一文详解Mongodb数据库,适合大数据存储
一文详解Mongodb数据库,适合大数据存储 2022年全球人工智能软件市场规模将达625亿美元 相比2021年增长21.3%
2022年全球人工智能软件市场规模将达625亿美元 相比2021年增长21.3%