-- 语法糖+1
WITH orders_with_total AS (
SELECT
order_id
, price + tax AS total
FROM Orders
)
SELECT
order_id
, SUM(total)
FROM orders_with_total
GROUP BY
order_id;
INSERT INTO target_table
SELECT * FROM Orders
INSERT INTO target_table
SELECT order_id, price + tax FROM Orders
INSERT INTO target_table
-- 自定义 Source 的数据
SELECT order_id, price FROM (VALUES (1, 2.0), (2, 3.1)) AS t (order_id, price)
INSERT INTO target_table
SELECT price + tax FROM Orders WHERE id = 10
-- 使用 UDF 做字段标准化处理
INSERT INTO target_table
SELECT PRETTY_PRINT(order_id) FROM Orders
-- 过滤条件
Where id > 3
其实理解一个 SQL 最后生成的任务是怎样执行的,最好的基础方式就是理解其语义。
以下面的语义 SQL 为例,我们来介绍下其在离线中和在实时中执行的区别,对比学习一下,大家就比较清楚了。

INSERT INTO target_table
SELECT PRETTY_PRINT(order_id) FROM Orders
Where id > 3
这个 SQL 对应的实时任务,假设 Orders 为 kafka,target_table 也为 Kafka,在执行时,会生成三个算子:

可以看到这个实时任务的所有算子是以一种 pipeline 模式运行的,所有的算子在同一时刻都是处于 running 状态的,24 小时一直在运行,实时任务中也没有离线中常见的分区概念。

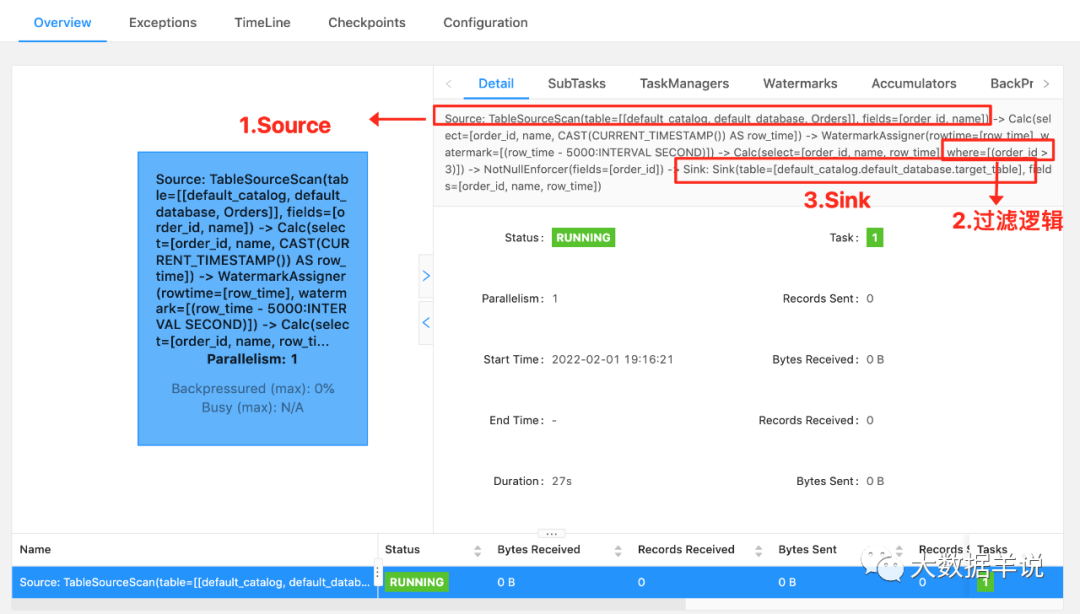
select & where
关于看如何看一段 Flink SQL 最终的执行计划:
最好的方法就如上图,看 Flink web ui 的算子图,算子图上详细的标记清楚了每一个算子做的事情。以上图来说,我们可以看到主要有三个算子:
可以看到 Flink SQL 具体执行了哪些操作是非常详细的标记在算子图上。所以小伙伴萌一定要学会看算子图,这是掌握 debug、调优前最基础的一个技巧。
那么如果这个 SQL 放在 Hive 中执行时,假设其中 Orders 为 Hive 表,target_table 也为 Hive 表,其也会生成三个类似的算子(虽然实际可能会被优化为一个算子,这里为了方便对比,划分为三个进行介绍),离线和实时任务的执行方式完全不同:
可以看到离线任务的算子是分阶段(stage)进行运行的,每一个 stage 运行结束之后,然后下一个 stage 开始运行,全部的 stage 运行完成之后,这个离线任务就跑结束了。
注意:
很多小伙伴都是之前做过离线数仓的,熟悉了离线的分区、计算任务定时调度运行这两个概念,所以在最初接触 Flink SQL 时,会以为 Flink SQL 实时任务也会存在这两个概念,这里博主做一下解释。
INSERT into target_table
SELECT
DISTINCT id
FROM Orders也是拿离线和实时做对比。
这个 SQL 对应的实时任务,假设 Orders 为 kafka,target_table 也为 Kafka,在执行时,会生成三个算子:
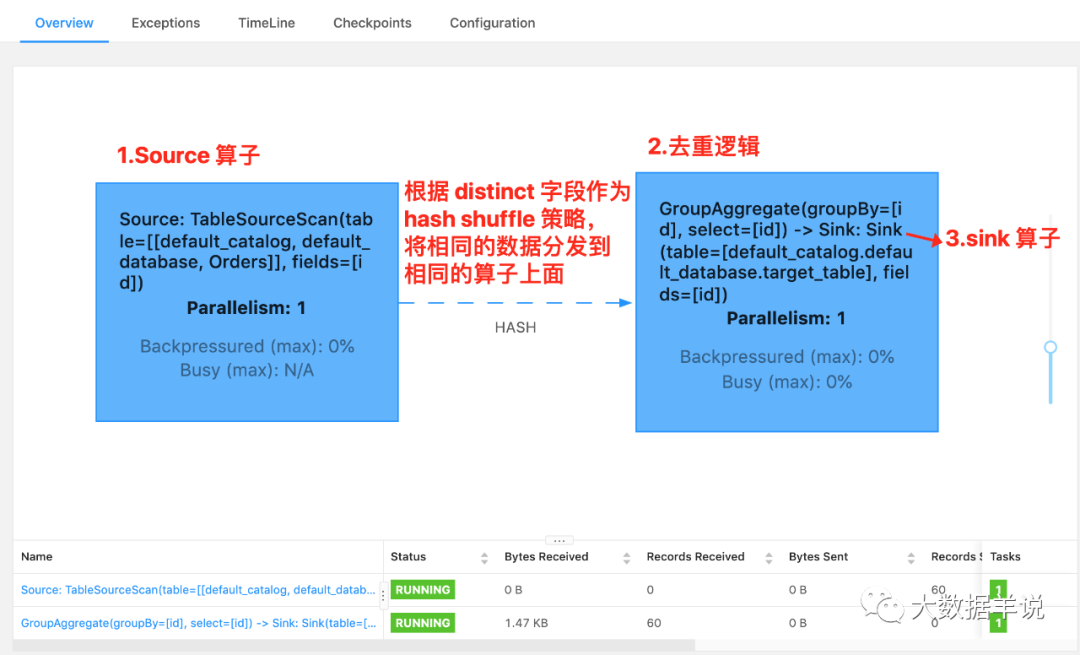
select distinct
注意:
对于实时任务,计算时的状态可能会无限增长。
状态大小取决于不同 key(上述案例为 id 字段)的数量。为了防止状态无限变大,我们可以设置状态的 TTL。但是这可能会影响查询结果的正确性,比如某个 key 的数据过期从状态中删除了,那么下次再来这么一个 key,由于在状态中找不到,就又会输出一遍。
那么如果这个 SQL 放在 Hive 中执行时,假设其中 Orders 为 Hive 表,target_table 也为 Hive 表,其也会生成三个相同的算子(虽然可能会被优化为一个算子,这里为了方便对比,划分为三个进行介绍),但是其和实时任务的执行方式完全不同:
(责任编辑:休闲)
海外客商抢抓中国新春机遇 境外消费回流对进口消费产生一定带动作用
 哥斯达黎加的雨林水、斯洛伐克的水晶杯、南非的牛排、斯洛文尼亚的南瓜籽油……今年红火的中国新春消费市场吸引了一批海外客商,这些“全球年货搬运工”全年不
...[详细]
哥斯达黎加的雨林水、斯洛伐克的水晶杯、南非的牛排、斯洛文尼亚的南瓜籽油……今年红火的中国新春消费市场吸引了一批海外客商,这些“全球年货搬运工”全年不
...[详细] 囤卫生纸竟成流行?“全国多地纸巾涨价”引发关注。有公司迂回表示称:停机检修中。市场到底有没有出现“洛阳纸贵”?消费者感受明不明显?纸巾涨价缘由何在?5月
...[详细]
囤卫生纸竟成流行?“全国多地纸巾涨价”引发关注。有公司迂回表示称:停机检修中。市场到底有没有出现“洛阳纸贵”?消费者感受明不明显?纸巾涨价缘由何在?5月
...[详细] 12月10日,严寒细雨,达川区市场监管局党组书记范爱华率机关党委书记王淼、办公室相关人员一行5人深入达川西部片区边远的石桥镇歇马庙村调研乡村振兴工作,为乡村振兴战略下如何实现“产业兴旺&r
...[详细]
12月10日,严寒细雨,达川区市场监管局党组书记范爱华率机关党委书记王淼、办公室相关人员一行5人深入达川西部片区边远的石桥镇歇马庙村调研乡村振兴工作,为乡村振兴战略下如何实现“产业兴旺&r
...[详细] 上周(5月24日至28日),A股市场持续活跃。同花顺数据显示,三大指数周内涨幅均超3%。两融余额快速上行,截至5月27日,沪深两融余额为17117.67亿元,连续五个交易日增加。与此同时,北向资金周内
...[详细]
上周(5月24日至28日),A股市场持续活跃。同花顺数据显示,三大指数周内涨幅均超3%。两融余额快速上行,截至5月27日,沪深两融余额为17117.67亿元,连续五个交易日增加。与此同时,北向资金周内
...[详细] 美信网络技术有限公司地址在重庆市渝北区龙兴镇迎龙大道19号,注册资本是5,000万元。
...[详细]
美信网络技术有限公司地址在重庆市渝北区龙兴镇迎龙大道19号,注册资本是5,000万元。
...[详细] 原标题:OpenAI已向美国专利局提交“GPT-5”商标申请)2023年7月31日,美国商标律师Josh Gerben发推称,OpenAI已于7月18日向美国专利商标局USPTO)提交“GPT-5”商
...[详细]
原标题:OpenAI已向美国专利局提交“GPT-5”商标申请)2023年7月31日,美国商标律师Josh Gerben发推称,OpenAI已于7月18日向美国专利商标局USPTO)提交“GPT-5”商
...[详细] 随着“两压一降”监管政策的持续推出和市场良好投资信誉的维持,我国信托产品存量规模连续三个月保持在20万亿元以内。与此同时,今年一季度,我国信托产品投资者数量新增近8万,连续五个
...[详细]
随着“两压一降”监管政策的持续推出和市场良好投资信誉的维持,我国信托产品存量规模连续三个月保持在20万亿元以内。与此同时,今年一季度,我国信托产品投资者数量新增近8万,连续五个
...[详细] 证监会28日公布首批证券公司“白名单”,共包括29家证券公司,中信证券、中金公司、国泰君安、银河证券、中信建投、申万宏源、国信证券、平安证券等主要券商均在列。证监会表示,按照&
...[详细]
证监会28日公布首批证券公司“白名单”,共包括29家证券公司,中信证券、中金公司、国泰君安、银河证券、中信建投、申万宏源、国信证券、平安证券等主要券商均在列。证监会表示,按照&
...[详细]HM INTL HLDGS(08416.HK)2020年盈转亏至452.7万港元 基本每股净亏1.13港仙
 HM INTL HLDGS(08416.HK)公布,截至2020年12月31日止年度,公司实现收入1.2亿港元,同比减少8.42%;公司拥有人期内应占亏损452.7万港元,去年则溢利261.4万港元,
...[详细]
HM INTL HLDGS(08416.HK)公布,截至2020年12月31日止年度,公司实现收入1.2亿港元,同比减少8.42%;公司拥有人期内应占亏损452.7万港元,去年则溢利261.4万港元,
...[详细]深物业A(000011.SZ):控股股东完成无偿划转3803.789万股 股权未发生变动
 3 月 17日丨深物业A(000011.SZ)公布,之前公告披露,公司接到控股股东深圳市投资控股有限公司(“深投控”)下发的《深圳市投资控股有限公司关于深圳市物业发展(集团)股
...[详细]
3 月 17日丨深物业A(000011.SZ)公布,之前公告披露,公司接到控股股东深圳市投资控股有限公司(“深投控”)下发的《深圳市投资控股有限公司关于深圳市物业发展(集团)股
...[详细] 芝加哥农产品期价4日涨跌不一 大豆5月合约涨幅为0.21%
芝加哥农产品期价4日涨跌不一 大豆5月合约涨幅为0.21% 天喻信息(300205)融资余额2.89亿元 融券余额0元(03
天喻信息(300205)融资余额2.89亿元 融券余额0元(03 英媒:英国欲用本土狗“示好”中国游客
英媒:英国欲用本土狗“示好”中国游客 大生农业金融(01103.HK)发布公告:年度公司持有人应占亏损11.25亿元
大生农业金融(01103.HK)发布公告:年度公司持有人应占亏损11.25亿元
