def get_data(sql,聊聊host='',port=2000,user='',password='',db=''): # 支持doris import pymysql connect = pymysql.connect(host=host,port=port,user=user,password=password,db=db,charset='utf8') cursor = connect.cursor() cursor.execute('SET query_timeout = 216000;') #单位秒 cursor.execute(sql) result = cursor.fetchall() for row in result: pass # 存储格式可以自行控制 cursor.close() connect.close() return result主要参数介绍:
read.jdbc(url=url,table=remote_table,column='item_sku_id',numPartitions=50,lowerBound=lowerBound, upperBound=upperBound,properties=prop)url:格式如'jdbc:mysql://**.jd.com:2000/数据库名?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&failOverReadOnly=false&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=Asia/Shanghai'
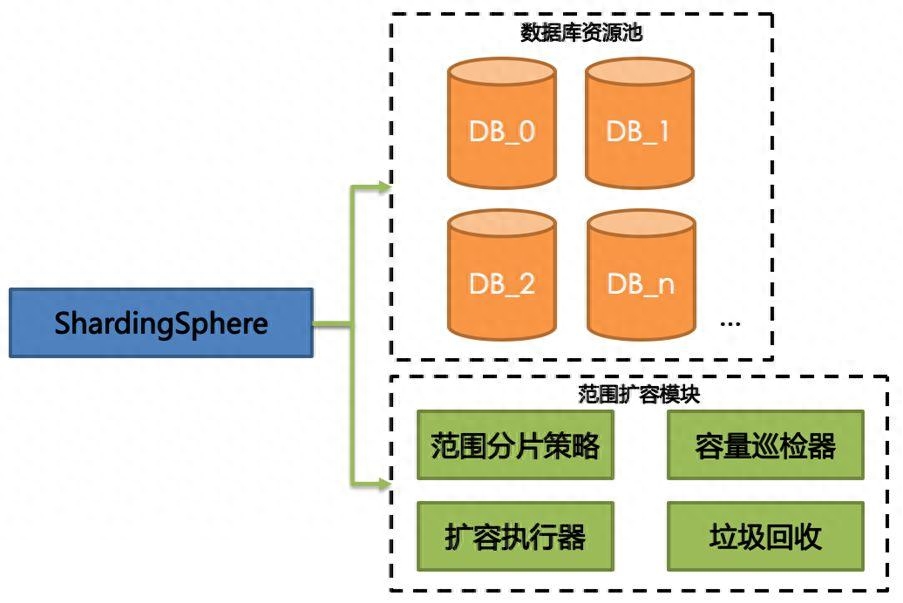
table:可以是表名,也可以是查询sql(也即支持条件查询),如果是sql,格式如"(SELECT count(*) sku FROM rule_price_result where dt='2023-05-10') AS tmp"
numPartitions:控制并发节点个数
lowerBound+upperBound和properties二选一,控制每个节点读取的数据范围。
lowerBound+upperBound方式:指定读取最低和最高值,spark会结合分区个数和最低最高边界机械做分割。
如果数据分布有倾斜,可以通过predicates列表自行控制范围。
责任编辑:武晓燕 来源: 今日头条 doris数据单节点作者:京东零售 赵奇猛
来源:京东云开发者社区
(责任编辑:时尚)
华阳股份(600348.SH)公布消息:拟开展应收账款保理业务
 华阳股份(600348.SH)公布,公司及公司下属煤炭销售公司拟将一定期间内向华能国际电力股份有限公司(“华能国际”)电厂供应煤炭所形成的应收账款用于办理应收账款保理融资业务。
...[详细]
华阳股份(600348.SH)公布,公司及公司下属煤炭销售公司拟将一定期间内向华能国际电力股份有限公司(“华能国际”)电厂供应煤炭所形成的应收账款用于办理应收账款保理融资业务。
...[详细]通胀难挡消费热情 涨价助力宝洁(PG.US)Q1营收、利润双双超预期
 原标题:通胀难挡消费热情 涨价助力宝洁(PG.US)Q1营收、利润双双超预期)智通财经APP获悉,10月18日美股盘前,宝洁(PG.US)公布了营收和利润均超预期的第一季度业绩,原因是尽管产品销量下降
...[详细]
原标题:通胀难挡消费热情 涨价助力宝洁(PG.US)Q1营收、利润双双超预期)智通财经APP获悉,10月18日美股盘前,宝洁(PG.US)公布了营收和利润均超预期的第一季度业绩,原因是尽管产品销量下降
...[详细] 【手机中国行情】对于千元机来说,其由于成本所限,往往存在两个较大的痛点,一是颜值不够,二是难以长久使用。不过在不久前,OPPO千元新机A2x正式开售。新机售价1099元起,其针对上述两大痛点“对症下药
...[详细]
【手机中国行情】对于千元机来说,其由于成本所限,往往存在两个较大的痛点,一是颜值不够,二是难以长久使用。不过在不久前,OPPO千元新机A2x正式开售。新机售价1099元起,其针对上述两大痛点“对症下药
...[详细] 雷柏VT300电竞鼠标搭载PMW3327游戏传感器,高精准度游戏传感,点对点实时还原战场、实时还原每一个精彩瞬间。继雷柏高端电竞VT系列首款旗舰级鼠标VT900上市之后,VT系列第二款电竞游戏鼠标——
...[详细]
雷柏VT300电竞鼠标搭载PMW3327游戏传感器,高精准度游戏传感,点对点实时还原战场、实时还原每一个精彩瞬间。继雷柏高端电竞VT系列首款旗舰级鼠标VT900上市之后,VT系列第二款电竞游戏鼠标——
...[详细] 低值股是什么意思?低值股指市价偏低的股票,一般属于冷门股。由于股票投资特别是短线投资有着“低价进、高价出” 的原则,而高价股往往风险较大且赚头不大,因此,投资于低值股往往是理想
...[详细]
低值股是什么意思?低值股指市价偏低的股票,一般属于冷门股。由于股票投资特别是短线投资有着“低价进、高价出” 的原则,而高价股往往风险较大且赚头不大,因此,投资于低值股往往是理想
...[详细] 【CNMO新闻】作为上半年最重要的电商购物节,618年中大促已落下帷幕。虽然商家们捷报频传、交易额再创新高,但同时也出现了一些问题。6月30日,中消协发布2022年“618”消费维权舆情分析报告。CN
...[详细]
【CNMO新闻】作为上半年最重要的电商购物节,618年中大促已落下帷幕。虽然商家们捷报频传、交易额再创新高,但同时也出现了一些问题。6月30日,中消协发布2022年“618”消费维权舆情分析报告。CN
...[详细]不用越狱!iPhone也能跑Windows和Linux,这款开源神器粉了
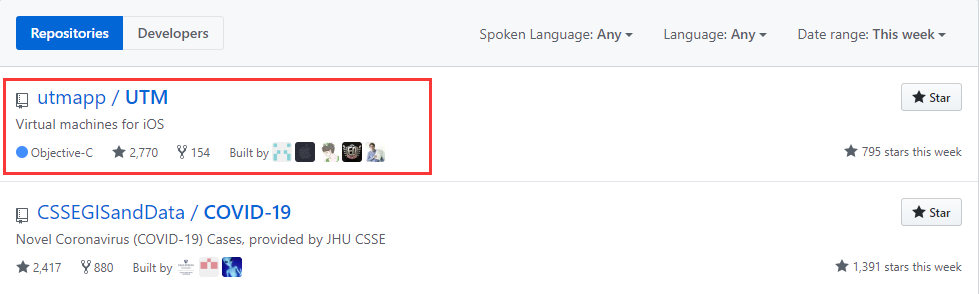 不用越狱!iPhone也能跑Windows和Linux,这款开源神器粉了作者:猿妹 2020-03-04 10:54:54新闻 开源 近日,猿妹发现一群国外开发者共同创建了一款名为 UTM 的虚拟机,
...[详细]
不用越狱!iPhone也能跑Windows和Linux,这款开源神器粉了作者:猿妹 2020-03-04 10:54:54新闻 开源 近日,猿妹发现一群国外开发者共同创建了一款名为 UTM 的虚拟机,
...[详细] 【CNMO新闻】最近这一段视频,爱奇艺、优酷等视频网站频频在互联网上引起了不少争议。不久之前,爱奇艺App限制用户进行投屏和HDMI视频传输,促使用户购买价格更高的白金会员引起了很多用户的愤怒,更是让
...[详细]
【CNMO新闻】最近这一段视频,爱奇艺、优酷等视频网站频频在互联网上引起了不少争议。不久之前,爱奇艺App限制用户进行投屏和HDMI视频传输,促使用户购买价格更高的白金会员引起了很多用户的愤怒,更是让
...[详细] 从渤海银行南京分行到浦发银行南通分行,接二连三发生的企业存款质押“风波”,引起了大众的热切关注。监管层也发声了,银保监会新闻发言人11月19日表示,近期,个别商业银行与企业客户
...[详细]
从渤海银行南京分行到浦发银行南通分行,接二连三发生的企业存款质押“风波”,引起了大众的热切关注。监管层也发声了,银保监会新闻发言人11月19日表示,近期,个别商业银行与企业客户
...[详细] 【手机中国新闻】10月17日,手机中国了解到,市场研究机构Counterpoint Research发布了三季度全球智能手机市场报告,报告显示今年第三季度全球智能手机市场整体销量同比下滑8%环比增长2
...[详细]
【手机中国新闻】10月17日,手机中国了解到,市场研究机构Counterpoint Research发布了三季度全球智能手机市场报告,报告显示今年第三季度全球智能手机市场整体销量同比下滑8%环比增长2
...[详细] 国家统计局:11月PMI为50.1% 制造业重回扩张区间
国家统计局:11月PMI为50.1% 制造业重回扩张区间 2023Q3电视市场复苏明显,环比增长1.2%
2023Q3电视市场复苏明显,环比增长1.2% 比亚迪7月新能源汽车销量16.25万辆 全年累计超80万辆 -
比亚迪7月新能源汽车销量16.25万辆 全年累计超80万辆 - 三种可视化方法,手把手教你用R绘制地图网络图!
三种可视化方法,手把手教你用R绘制地图网络图! 先用后付不还会封号吗 先用后付逾期过后能不能恢复?
先用后付不还会封号吗 先用后付逾期过后能不能恢复?
