
对于高精度采样结果,大数其数值最大可能需要3字节,据变最少1字节,长存储算采用标准C的嵌入基础数据类型,U16太小无法满足需求,式算U32则浪费内存。法之法当样本量很大时,其占用的空间问题便突显出来。能否采用变长数据类型存储呢?对小数据采用U8,大数据采用U32,随着数值大小动态分配存储空间,就是本文的讨论的重点。
U32的空间其数值范围最大接近2^32,该值非常大,实际数值范围远小于它,高位必然为0。例如U32表示1使用0x00000001,前面位都是0,其表达的数值和U8的0x01是一样的,前面重复的一串0属于冗余数据区,是可以剔除的。

假设5个数据D0..4,原本每个数据固定为U32类型,将其高位冗余0去掉,再拼接到U8的一维数组,则占用的空间和大大缩小。思路的核心是把 U32 或者U64 数组裁剪后拼接成U8 数组,同时确保使用时可

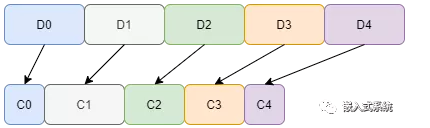

根据U8 数组中存储的信息将对应的数值还原。
假设有0x00000001、0x00000101、0x00000001三个数据,其有效部分是0x01、0x0101、0x01,如果直接拼接在一起,则没法区分0x01010101的含义。因此数据在去掉高位0之后,还需进行编码标记,便于后续解析还原。
数据编码的主要作用是标记当前数据占用多少连续字节,有两种方案:
1、固定位来定义字节长度(2位可以表示4字节)
一字节:00
(责任编辑:探索)
 清明节一般放假三天,部分特殊人员可能需要值班,所以在清明节期间或是无法外出游玩了。临近清明节期间,你打算去哪里游玩呢?目前数据指出,清明假期酒店预订量上升,同比增长4.5倍。去年清明节,由于需要做好疫
...[详细]
清明节一般放假三天,部分特殊人员可能需要值班,所以在清明节期间或是无法外出游玩了。临近清明节期间,你打算去哪里游玩呢?目前数据指出,清明假期酒店预订量上升,同比增长4.5倍。去年清明节,由于需要做好疫
...[详细] 缓存穿透、缓存击穿和缓存雪崩实践作者:xiaolyuh 2019-11-05 14:24:31存储 存储软件 我们使用缓存的主要目是提升查询速度和保护数据库等稀缺资源不被占满。而缓存最常见的问题是缓存
...[详细]
缓存穿透、缓存击穿和缓存雪崩实践作者:xiaolyuh 2019-11-05 14:24:31存储 存储软件 我们使用缓存的主要目是提升查询速度和保护数据库等稀缺资源不被占满。而缓存最常见的问题是缓存
...[详细] 鸿蒙轻量级数据库DatabaseHelper基本用法和技巧作者:xq9527 2021-12-06 15:11:34数据库 其他数据库 今天要讲的是鸿蒙里面轻量级数据DatabaseHelper基本用
...[详细]
鸿蒙轻量级数据库DatabaseHelper基本用法和技巧作者:xq9527 2021-12-06 15:11:34数据库 其他数据库 今天要讲的是鸿蒙里面轻量级数据DatabaseHelper基本用
...[详细] 由弥渳工作室打造的《实习班主任》是一款独特而极富创意的校园模拟养成游戏,将于steam平台发售。在一般的校园类游戏中玩家通常都是扮演一名高中生在校园中体验高中生活和学习,但《实习班主任》这款游戏将区别
...[详细]
由弥渳工作室打造的《实习班主任》是一款独特而极富创意的校园模拟养成游戏,将于steam平台发售。在一般的校园类游戏中玩家通常都是扮演一名高中生在校园中体验高中生活和学习,但《实习班主任》这款游戏将区别
...[详细] 农行银行卡默认开通小额免密免签支付功能,虽然平时消费方便,但也存在安全隐患,那么在农行掌上银行上要怎么关闭小额免密支付功能呢?农行掌上银行怎么关闭小额免密支付?【1】首先在手机上打开并登录农业银行Ap
...[详细]
农行银行卡默认开通小额免密免签支付功能,虽然平时消费方便,但也存在安全隐患,那么在农行掌上银行上要怎么关闭小额免密支付功能呢?农行掌上银行怎么关闭小额免密支付?【1】首先在手机上打开并登录农业银行Ap
...[详细] 因为疫情的问题,不少公司在最近都发出了通告宣布将不参加今年于西班牙巴塞罗那举办的MWC 2020活动,不过还是有一些厂商通过提前隔离要参展的员工等方法努力的要参加这次活动。华为方面,据据huaweic
...[详细]
因为疫情的问题,不少公司在最近都发出了通告宣布将不参加今年于西班牙巴塞罗那举办的MWC 2020活动,不过还是有一些厂商通过提前隔离要参展的员工等方法努力的要参加这次活动。华为方面,据据huaweic
...[详细]iPhone7十大新特性:双摄像头、无线充电技术等功能都在这里
 有消息称苹果凭借iPhone6s和iPhone6s Plus的热卖,在中国市场已经超过小米华为等品牌,并占据了销量前五中的两个名次,可见国人对这两款手机的喜爱。为此,我们不妨来盘点iPhone 7十个
...[详细]
有消息称苹果凭借iPhone6s和iPhone6s Plus的热卖,在中国市场已经超过小米华为等品牌,并占据了销量前五中的两个名次,可见国人对这两款手机的喜爱。为此,我们不妨来盘点iPhone 7十个
...[详细] 今年年初以来有关Papi酱的新闻开始密集出现在各大媒体网站,且从未间断。作为内容从业者,时不时被这位“集美貌才华于一身”的奇女子刷屏早已是家常便饭,从最初的新鲜,到审美疲劳,有时虽不胜其烦,但也无可奈
...[详细]
今年年初以来有关Papi酱的新闻开始密集出现在各大媒体网站,且从未间断。作为内容从业者,时不时被这位“集美貌才华于一身”的奇女子刷屏早已是家常便饭,从最初的新鲜,到审美疲劳,有时虽不胜其烦,但也无可奈
...[详细] 外汇行情与股价有密切的联系。一般来说,如果一国的货币是实行升值的基本方针,股价便会上涨,一旦其货币贬值,股价即随之下跌。所以外汇的行情会带给股市以很大的影响。在当代国际贸易迅速发展的潮流中,汇率对一国
...[详细]
外汇行情与股价有密切的联系。一般来说,如果一国的货币是实行升值的基本方针,股价便会上涨,一旦其货币贬值,股价即随之下跌。所以外汇的行情会带给股市以很大的影响。在当代国际贸易迅速发展的潮流中,汇率对一国
...[详细]明明国产手机已经崛起了,为什么很多人买高端机还是只认准iPhone
 明明国产手机已经崛起了,为什么很多人买高端机还是只认准iPhone作者:黑猫评测 2021-07-28 21:32:43移动开发 移动应用 各大国产手机厂商都喜欢号称自己站稳了高端市场,但是我特别想问
...[详细]
明明国产手机已经崛起了,为什么很多人买高端机还是只认准iPhone作者:黑猫评测 2021-07-28 21:32:43移动开发 移动应用 各大国产手机厂商都喜欢号称自己站稳了高端市场,但是我特别想问
...[详细] 四川巴中恩阳机场新增航线直通18个城市 去年旅客吞吐量38.2万人次
四川巴中恩阳机场新增航线直通18个城市 去年旅客吞吐量38.2万人次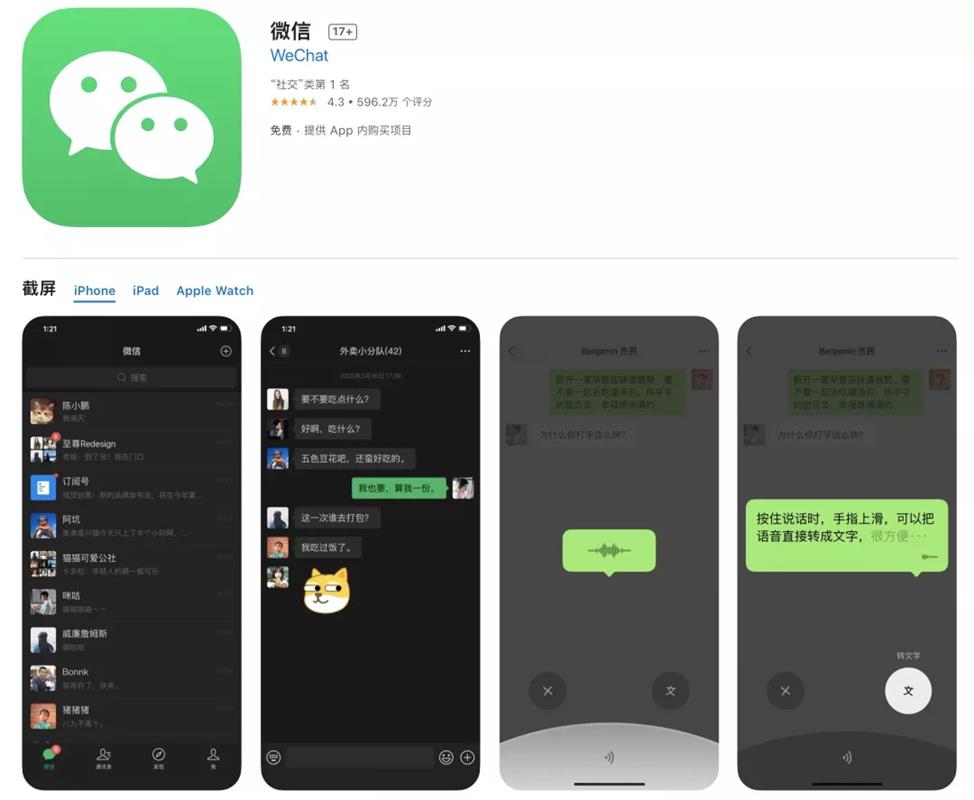 腾讯高手都在学的「感知性模式设计」是什么?
腾讯高手都在学的「感知性模式设计」是什么?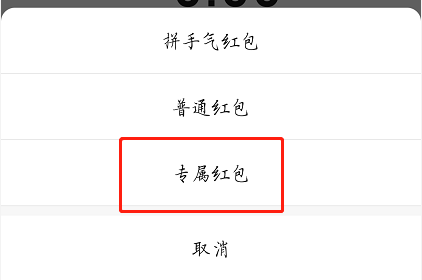 新版微信隐藏6个实用功能,强大又良心,可惜知道的人没几个
新版微信隐藏6个实用功能,强大又良心,可惜知道的人没几个 iBASE首发AMD EPYC准系统服务器:八核功耗仅30W
iBASE首发AMD EPYC准系统服务器:八核功耗仅30W 2022年全球人工智能软件市场规模将达625亿美元 相比2021年增长21.3%
2022年全球人工智能软件市场规模将达625亿美元 相比2021年增长21.3%
