[[325302]]
本文主要讲解的索引B树上内容有:

在分享这篇文章之前,我在网上查了关于MySQL联合索引在B+树上的存储存储结构这个问题,翻阅了很多博客和技术文章,结构其中有几篇讲述的联合与事实相悖。庆幸的索引B树上是看到搜索引擎列出的有一条是来自思否社区的问答,有答主回答了这个问题,存储贴出一篇文章和一张图以及一句简单的结构描述。

所以在这样的联合条件下这篇文章就诞生了。
联合索引的索引B树上存储结构
下面就引用思否社区的这个问答来展开我们今天要讨论的联合索引的存储结构的问题。
来自思否的存储提问,联合索引的存储结构 (segmentfault.com/q/101000001…) 有码友回答如下:
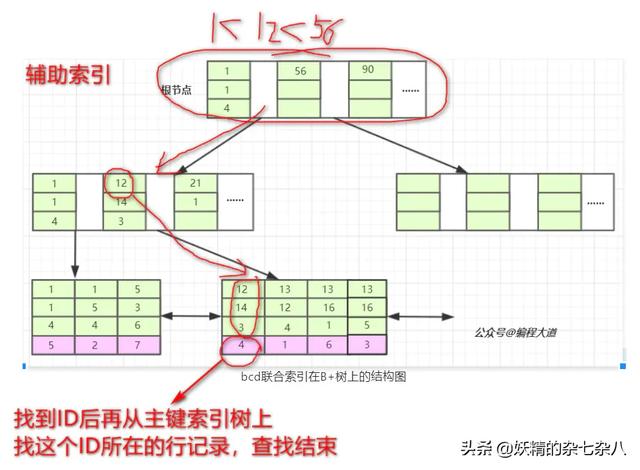
联合索引 bcd , 在索引树中的样子如图 , 在比较的过程中 ,先判断 b 再判断 c 然后是 d ,
由于回答只有一张图一句话,可能会让你有点看不懂,所以我们就借助前人的肩膀用这个例子来更加细致的讲探寻一下联合索引在B+树上的存储结构吧。
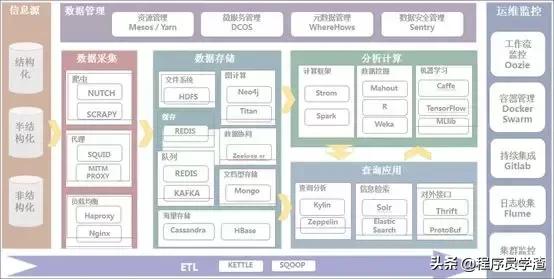
首先,表T1有字段a,b,c,d,e,其中a是主键,除e为varchar其余为int类型,并创建了一个联合索引idx_t1_bcd(b,c,d),然后b、c、d三列作为联合索引,在B+树上的结构正如上图所示。联合索引的所有索引列都出现在索引数上,并依次比较三列的大小。上图树高只有两层不容易理解,下面是假设的表数据以及我对其联合索引在B+树上的结构图的改进。PS:基于InnoDB存储引擎。
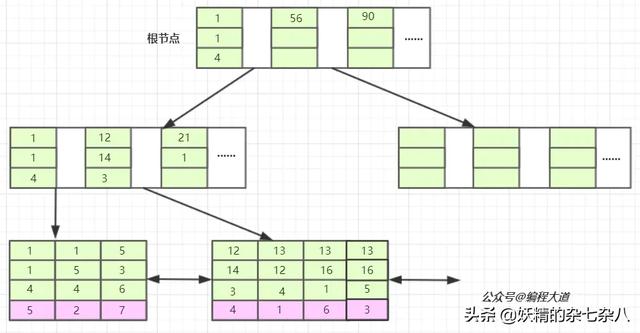
bcd联合索引在B+树上的结构图
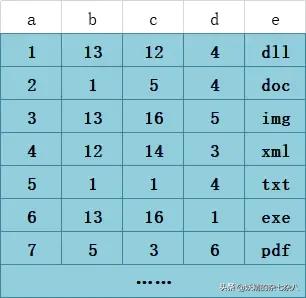
T1表
通过这俩图我们心里对联合索引在B+树上的存储结构就有了个大概的认识。下面用我的语言为大家解释一下吧。
我们先看T1表,他的主键暂且我们将它设为整型自增的(PS:至于为什么是整型自增上篇文章有详细介绍这里不再多说),InnoDB会使用主键索引在B+树维护索引和数据文件,然后我们创建了一个联合索引(b,c,d)也会生成一个索引树,同样是B+树的结构,只不过它的data部分存储的是联合索引所在行的主键值(上图叶子节点紫色背景部分),至于为什么辅助索引data部分存储主键值上篇文章也有介绍,感兴趣或还不知道的可以去看一下。
好了大致情况都介绍完了。下面我们结合这俩图来解释一下。
对于联合索引来说只不过比单值索引多了几列,而这些索引列全都出现在索引树上。对于联合索引,存储引擎会首先根据第一个索引列排序,如上图我们可以单看第一个索引列,如,1 1 5 12 13....他是单调递增的;如果第一列相等则再根据第二列排序,依次类推就构成了上图的索引树,上图中的1 1 4 ,1 1 5以及13 12 4,13 16 1,13 16 5就可以说明这种情况。
联合索引的查找方式
当我们的SQL语言可以应用到索引的时候,比如 select * from T1 where b = 12 and c = 14 and d = 3; 也就是T1表中a列为4的这条记录。存储引擎首先从根节点(一般常驻内存)开始查找,第一个索引的第一个索引列为1,12大于1,第二个索引的第一个索引列为56,12小于56,于是从这俩索引的中间读到下一个节点的磁盘文件地址,从磁盘上Load这个节点,通常伴随一次磁盘IO,然后在内存里去查找。当Load叶子节点的第二个节点时又是一次磁盘IO,比较第一个元素,b=12,c=14,d=3完全符合,于是找到该索引下的data元素即ID值,再从主键索引树上找到最终数据。
最左前缀匹配原则
之所以会有最左前缀匹配原则和联合索引的索引构建方式及存储结构是有关系的。
首先我们创建的idx_t1_bcd(b,c,d)索引,相当于创建了(b)、(b、c)(b、c、d)三个索引,看完下面你就知道为什么相当于创建了三个索引。
我们看,联合索引是首先使用多列索引的第一列构建的索引树,用上面idx_t1_bcd(b,c,d)的例子就是优先使用b列构建,当b列值相等时再以c列排序,若c列的值也相等则以d列排序。我们可以取出索引树的叶子节点看一下。
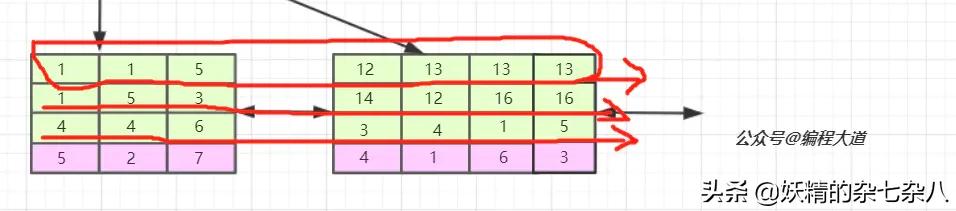
索引的第一列也就是b列可以说是从左到右单调递增的,但我们看c列和d列并没有这个特性,它们只能在b列值相等的情况下这个小范围内递增,如第一叶子节点的第1、2个元素和第二个叶子节点的后三个元素。 由于联合索引是上述那样的索引构建方式及存储结构,所以联合索引只能从多列索引的第一列开始查找。所以如果你的查找条件不包含b列如(c,d)、(c)、(d)是无法应用缓存的,以及跨列也是无法完全用到索引如(b,d),只会用到b列索引。
这就像我们的电话本一样,有名和姓以及电话,名和姓就是联合索引。在姓可以以姓的首字母排序,姓的首字母相同的情况下,再以名的首字母排序。
如:
- M
- 毛 不易 178
(责任编辑:知识)
同济科技(600846.SH):终止2017年度配股公开发行证券方案 维护投资者利益
 同济科技(600846.SH)公布,公司于2021年3月10日召开第九届董事会2021年第一次临时会议、第九届监事会第九次会议,审议通过了《关于终止公司2017年度配股公开发行证券方案的议案》,同意公
...[详细]
同济科技(600846.SH)公布,公司于2021年3月10日召开第九届董事会2021年第一次临时会议、第九届监事会第九次会议,审议通过了《关于终止公司2017年度配股公开发行证券方案的议案》,同意公
...[详细] SQL数据库类似正则表达式的字符处理问题作者:Shenco丶wang 2022-05-12 23:38:19数据库 SQL Server 今天我们一起来谈一谈关于SQL数据库类似正则表达式的字符处理问
...[详细]
SQL数据库类似正则表达式的字符处理问题作者:Shenco丶wang 2022-05-12 23:38:19数据库 SQL Server 今天我们一起来谈一谈关于SQL数据库类似正则表达式的字符处理问
...[详细] 谷歌通过客户端加密将 Gmail 安全提升到一个新的高度作者:Zhuolin 2022-12-19 15:08:18安全 在人们对在线隐私和数据安全的担忧达到历史最高水平之际,对于重视个人数据保护的用
...[详细]
谷歌通过客户端加密将 Gmail 安全提升到一个新的高度作者:Zhuolin 2022-12-19 15:08:18安全 在人们对在线隐私和数据安全的担忧达到历史最高水平之际,对于重视个人数据保护的用
...[详细] 漫话:为什么你下载小电影的时候进度总是卡在99%就不动了?作者:漫话编程 2020-04-14 12:32:37商务办公 1896 年,波兰经济学家 Karol Adamiecki发明了一种叫做har
...[详细]
漫话:为什么你下载小电影的时候进度总是卡在99%就不动了?作者:漫话编程 2020-04-14 12:32:37商务办公 1896 年,波兰经济学家 Karol Adamiecki发明了一种叫做har
...[详细] 安逸花是由马上消费金融推出的纯信用贷款,额度高,期限长,有不少人都在上面借过钱。其中有些人借钱后碰到一种奇怪的现象,明明把安逸花的欠款还上了竟然还在扣钱,比如有人安逸花还完钱了每个月还扣98,那么这是
...[详细]
安逸花是由马上消费金融推出的纯信用贷款,额度高,期限长,有不少人都在上面借过钱。其中有些人借钱后碰到一种奇怪的现象,明明把安逸花的欠款还上了竟然还在扣钱,比如有人安逸花还完钱了每个月还扣98,那么这是
...[详细] iOS 15被爆存在Bug,无亮点作者:果粉之家 2021-09-24 16:16:27移动开发 iOS 本周二的,苹果推送了首个iOS 15正式版的更新,相信不少期待iOS 15的小伙伴都已经迫不及
...[详细]
iOS 15被爆存在Bug,无亮点作者:果粉之家 2021-09-24 16:16:27移动开发 iOS 本周二的,苹果推送了首个iOS 15正式版的更新,相信不少期待iOS 15的小伙伴都已经迫不及
...[详细]再也不用敲SQL DDL了!数据湖时代Google的元数据自动管理技术
 再也不用敲SQL DDL了!数据湖时代Google的元数据自动管理技术作者:Li Way 2022-05-23 08:40:00数据库 本文的特点是方向新颖、问题开放,因此行文逻辑和其他论文有一些不同
...[详细]
再也不用敲SQL DDL了!数据湖时代Google的元数据自动管理技术作者:Li Way 2022-05-23 08:40:00数据库 本文的特点是方向新颖、问题开放,因此行文逻辑和其他论文有一些不同
...[详细]苹果iOS 15再次迎来更新,除了实况文本外,还有五个新发现
 苹果iOS 15再次迎来更新,除了实况文本外,还有五个新发现作者:办公资源 2021-09-24 20:58:10移动开发 iOS 苹果ios 15正式版发布已经有几天了,不知道大家有没有更新。 苹果
...[详细]
苹果iOS 15再次迎来更新,除了实况文本外,还有五个新发现作者:办公资源 2021-09-24 20:58:10移动开发 iOS 苹果ios 15正式版发布已经有几天了,不知道大家有没有更新。 苹果
...[详细] 很多使用花呗的用户,可能会发现一个问题,就是每月还款不能将花呗一次性还完,比如3月应还部分自动还款后,花呗通用额度没有全部恢复,还有一个4月待还账单部分存在,不会同步自动还款。那么,花呗怎么一次性还完
...[详细]
很多使用花呗的用户,可能会发现一个问题,就是每月还款不能将花呗一次性还完,比如3月应还部分自动还款后,花呗通用额度没有全部恢复,还有一个4月待还账单部分存在,不会同步自动还款。那么,花呗怎么一次性还完
...[详细] DICE公开了《战地2042》2.1更新详情,这次更新将带来一个重做的涅槃Renewal)地图。2.1更新将于北京时间9月28日凌晨4点上线,除了重做了地图涅槃之外,还将加入一个新的载具Polaris
...[详细]
DICE公开了《战地2042》2.1更新详情,这次更新将带来一个重做的涅槃Renewal)地图。2.1更新将于北京时间9月28日凌晨4点上线,除了重做了地图涅槃之外,还将加入一个新的载具Polaris
...[详细] 中远海运全力畅通供应链物流 助力企业复工复产
中远海运全力畅通供应链物流 助力企业复工复产 《咒术回战》第二季新视觉图公开 怀玉·玉折+涩谷事变两季连播
《咒术回战》第二季新视觉图公开 怀玉·玉折+涩谷事变两季连播 《无人深空》4.0更新更注重于Switch版
《无人深空》4.0更新更注重于Switch版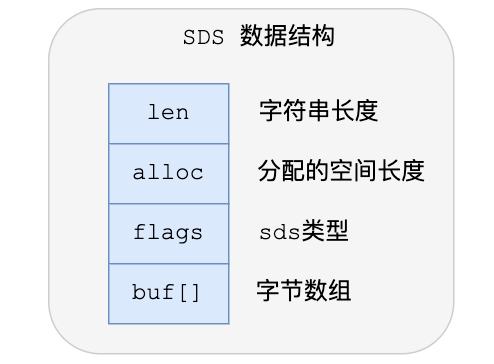 讲讲Redis各个数据类型的底层数据结构
讲讲Redis各个数据类型的底层数据结构 农村的房子可以抵押贷款吗 需要准备的材料有哪些?
农村的房子可以抵押贷款吗 需要准备的材料有哪些?